日志
转:Tcl与Design Compiler 5- 13
热度 3| ||
本文如果有错,欢迎留言更正;此外,转载请标明出处 http://www.cnblogs.com/IClearner/ ,作者:IC_learner
前面一直说到综合库/工艺库这些东西,现在就来讲讲讲综合库里面有什么东西,同时也讲讲synopsys的Design Ware库。主要内容分为三个部分:标准单元库、DC的设计对象、Design Ware库。
(1)标准单元库
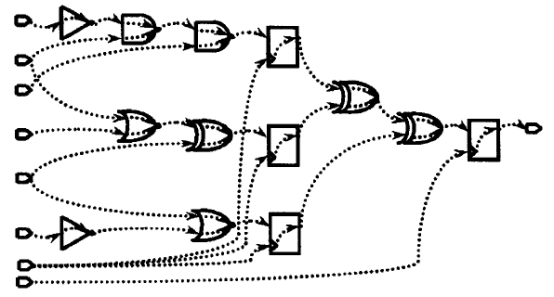
绝大多数的数字设计流程都是基于标准单元的半定制设计流程。标准单元库包含了反相器、缓冲、与非、或非、与或非、锁存器、触发器等等逻辑单元综合模型的物理信息,标准单元是完成通用功能的逻辑,具有同等的高度(宽度可以不同),这样方便了数字后端的自动布局布线。
①概述
一个ASIC综合库包括如下信息:
·一系列单元(包括单元的引脚)。
·每个单元的面积(在深亚微米中,一般用平方微米表示,在亚微米工艺下,一般用门来称呼,至于具体的单位,可以咨询半导体制造商)。
·每个输出引脚的逻辑功能。
·每个输入到输出的传递延时,输出到输出的传递延时;inout到输出的传递延时。
②内容与结构
Synopsys的工艺库是一个.lib文件,经过LC编译后,产生.db文件。工艺库文件主要包括如下信息:
·单元(cell)(的信息):(主要有)功能、时间(包括时序器件的约束,如建立和保持)、面积(面积的单位不在里面定义,可按照规律理解,一般询问半导体厂商)、功耗、测试等。
·连线负载模型(wire load models):电阻、电容、面积。
·工作环境/条件(Operating conditions):制程(process)(电压和温度的比例因数k,表示不同的环境之间,各参数缩放的比例)
·设计规则约束(Design ):最大最小电容、最大最小转换时间、最大最小扇出。
工艺库的结构如下所示:

文本描述如下所示:





我使用的TSMC90nm的工艺库,我用slow.lib这个库来给大家介绍:
这个库总共三万多行,不可能每一行都解说,因此我按照结构进行介绍。
打开这个.lib文件,可以看到最前面:

最前面的是这些注释,描述的是:制程(是慢的模型)、电压、温度等数据信息。
接下来才是真正的库的信息:
库组(大结构):
Library(library_name){
......
......
}
A首先是库的属性的描述:

下面是这张图的解释:
·通用属性描述(general attribute):
主要是工艺类型、延迟模型、替代交换方式、库特征、总线命名方式等信息
工艺类型:这个库没有给出,主要用来说明这个库是CMOS工艺还是FPGA工艺。默认是CMOS工艺。
延迟模型:指明在计算延迟时用的那个模型,主要有generic_cmos(默认值)、table-lookup(非线性模型)、piecewise-cmos(optional)、dcm(Delay Calculation Module)、polynomial。这个库使用的非线性模型。
替代交换方式:这里选的是匹配封装的方式。具体的信息可以查阅其他治疗或者询问半导体厂商。
库特征:报告延迟计算,也就是这个库具有延迟计算的特征。
总线命名方式:定义库中总线命名规则。例如:bus_naming_style:"Bus%spin%d";这个库没有进行总线规则的命名。
·库的文档资料属性(document attribute):
主要是库的版本、库的日期、还有注释。例如:
用库报告命令report_lib可显示日期例如:Date:"Wed Jun 22 12:31:54 2005"。
修正版属性定义库的版本号码,例如Revision:1.3;
注释属性用于报告report_lib命令所显示的信息,如版权或其他产品信息。例如:Comment:"Copyright (c) 2005 Artisan Components, Inc. All Rights Reserved.”
·定义单位属性(unit attribute):
Design Compiler工具本身是没有单位的。然而在建立工艺库和产生报告时,必须要有单位。库中有6个库级属性定义单位:time_ unit(时间单位)、voltage_unit(电压单位)、current_ unit(电流单位)、pulling_resistance_unit(上/下拉电阻单位)、capacitive_load_unit(电容负载单位)、leakage_power_unit(漏电功耗单位)。
单位属性确定测量的单位,例如可在库中用毫微秒(nanoseconds)或皮法拉(picofar-ads)作为时间和电容负载的单位。
注:关于面积的单位,前面已经说了,这里不再详述。
B接下来是环境描述:
主要包括操作条件(operation conditions)、临界条件定义(threshold definitions)、默认的一些环境属性(default attributes)、一些(时序、功耗)模型(templates)、比例缩放因子(k-factors)、I/O pad属性(pad attributes)、线负载模型(wire-loads)。
·操作条件(operation conditions):

在工艺库中,用操作条件设置了制程(process)、温度(temperature)、电压(voltage)与RC树模型(tree_type)。
在综合和静态时序分析时,DC要用到这些信息来计算电路的延迟,而库中的这组操作条件为基础(也就是nom_xxxx)操作条件。一个工艺库只有这么一组基础的操作条件,如果要使用不同的操作条件,则需要借助K参数了(见后面)。制程、温度、电压这些很好理解,下面主要说一下这个RC树模型(tree_type)。
tree-type属性定义了布局之前延时的计算方式。此外,线负载模型(后面有讲)是根据连线的扇出来估算连线的RC寄生参数的,RC如何分配就是根据这个tree-type属性来的。
连线延时(从驱动引脚的状态变化到每个接受单元输入引脚的状态变化,线负载模型设每个分枝的延迟是一样的。)的一个示例如下图所示:
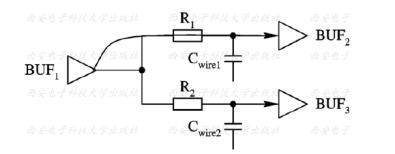
在这个简单的电路中,BUF1的输出驱动两个单元:BUF2与BUF3。在物理上,这是两根连线。而在网表中,两根连线用一个net来表示。
在布局前,假设这两根线有相同的寄生电阻与寄生电容,即Cwire1-Cwire2=R1-R2 。
假设我们想了解从BUF1的输出到BUF2的输入端的延时。这个延时实际上是给连线及BUF2的输入引脚负载进行充、放电所消耗的时间。
如何计算这个延时呢?tree-type就是为此而定义的。Tree-type有三种取值,这个延时就有三种计算模型,这三种模型有两种理解方式,这两种理解方式是等价的。
第一种理解方式的三种模型:
A:当它取值为worst-case-tree时,连线的寄生参数采用集总模型,即用Cwire*(Cwire 1+Cwire2)这个乘积表示连线的等效电容,Rwire(R1+R2)表示连线的等效电阻。C1表示BUF1输入引脚的等效电容。C2表示BUF2输入引脚的等效电容。从BUF 1到BUF2的延时计算模型下图所示:
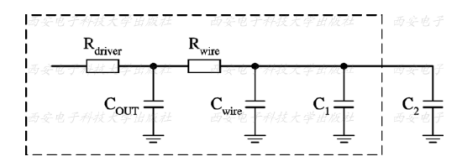
在这种模型中,net本身的延迟为Rwire*Cwire .
B:当tree-type取值为best-case-tree时,计算延时的RC模型如下图所示:
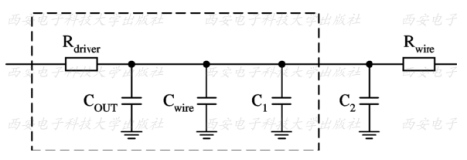
在这种模型中,Rwire为0,因此net本身的延时为0
C:当tree-type取值为balanced-tree时,计算延时的RC模型如下图所示:

在这种模型中,net的延时为Rwire*Cwire/(N^2)。这里N表示负载数目,本例中取值为2.
第二种理解方式的三种模型:

无论是从哪一种方式理解,这个库中使用的是平衡树的模型。
·临界条件定义(threshold definitions):
主要是定义一些极限值,比如时钟抖动的最大最小值、输出输出的上升下降沿的最大最小值等等信息,如下图所示:

·默认的一些环境属性(default attributes):
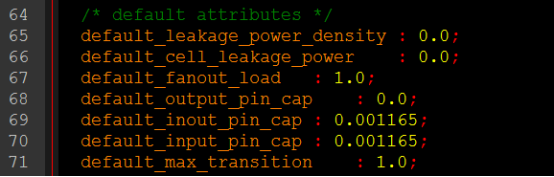
主要是默认漏电流功耗密度、标准单元的漏电流功耗、扇出负载最大值、输出引脚的电容、IO类型的端口电容、输入引脚的电容、最大转换时间。
·一些(时序、功耗)模型(templates):
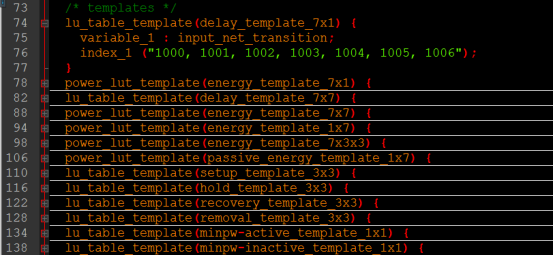
都是写查找表模型,主要是功耗(比如输入转移时间的功耗)、时序(比如输入线转换的延时、建立时间和保持时间的延时)等等,根据不同的操作环境,进行查表进行选择对应的参数。
·比例缩放因子(k-factors):
由于一般库中只有单元“nom_xxx”的值,为了计算不同的制程、电压和温度下单元的延迟(或者说是计算不同的操作条件),库中提供了比例缩放因子:

比例因子有许多,这里只是列举了这几个。
根据提供的K参数,DC按下面的公式计算不同的制程,电压和温度的单元延迟:
Delay derated = (nominal delay)*(1+(DP*KfactorP))*(1+(DV*KfactorV))*(1+(DT*KfactorT))
其中:
delta = current-nominal ;
DP = CP-NP,CP为current process,NP为nominal process;
DV=CV-NV,CV为current voltage,NP为nominal voltage;
DT=CT-NT,CT为current temperature,NT为nominal temperature.
KfactorP、KfactorV、KfactorT分别是对于的K参数,表示制程、电压、温度对延时的影响。
·I/Opad属性(pad attributes):
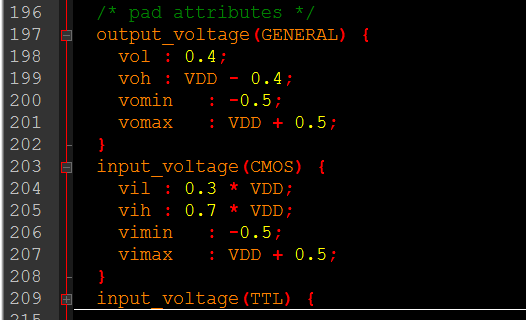
主要就是定义I/O引脚的电平属性,告诉你输入是COMS还是TTL,什么时候达到高电平、什么时候是低电平。
·线负载模型(wire-loads):
工艺库的线负载模型如下所示:
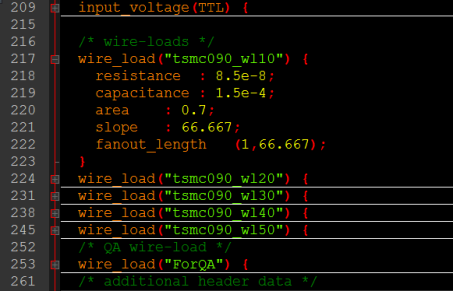
DC采用wire-load模型在布局前预估连线的延时。通常,在工艺库中,根据不同的芯片面积给出了几种模型(上图所示)。这些模型定义了电容、电阻与面积因子。此外,导线负载模型还设置了slope与fanout_length,fanout-length设置了与扇出数相关的导线的长度。
有时候,除了扇出与长度,该属性还包括其他参数的值(这个工艺库没有),例如average_capacitance、standard_deviation与number_of_nets,在DC产生导线负载模型时会自动写出这些值。对于超过fanout-length属性的节点,可将该导线分成斜率不同的几段,以确定它的值。
C工艺库剩下的全是标准单元(cell)的描述:如反相器、触发器、与非门、或非门的描述等:

·标准单元内容概述
综合库中的每个单元都包括一系列的属性,以描述功能、时序与其他的信息。 在单元的引脚描述中,包含了如下内容:输入引脚的fanout-load属性、输出引脚的max_fanout属性、输入或输出引脚的max_transition属性、输出或者inout引脚的max_capacitance属性。利用这些描述,可以对设计进行DRC(设计规则检查)。如果某个单元的输出最大只能接0.2pF的负载,但在实际综合的网表中却连接了0.3pF的负载,这时候综合工具就会报出DRC错误。
通常,fanout_load与max_fanout一起使用max_transition与max_capacitance一起使用。 如果一个节点的扇出为4,它驱动3个与非门,每个与非门的fanout-load是2,则这三个与非门无法被驱动(因为3*2>4)。
max_transition通常用于单元的输入引脚,max_capacitance一般用于单元的输出引脚。如果任何节点的transition时间大于引脚的max_transition值,则该节点不能连接。如果发生违例,则DC用一个具有更大max_capacitance值的单元来取代驱动单元。
在对输出引脚的描述中,给出了该引脚的功能定义,以及与输入弓}脚相关的延时。输入引脚定义了它的引脚电容与方向。这个电容值不能与max_capacitance值相混。DC利用输入引脚的电容值进行延时计算,而max_capacitance仅用来进行设计规则检查。
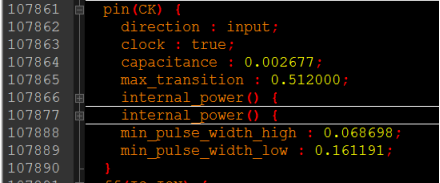
对于时序元件中的时钟引脚,专门用clock类型进行说明,如下所示:
注:许多设计者都会抱怨工艺库中对单元的DRC属性设置不当,这是由于库的能力是有限的所致。对于一个设计,综合库的DRC设置可能很合适,而对于另一个设计就可能不太合适。这时候,需要设计者对综合库进行“剪裁”。当然,这种“剪裁”必须比库中的定义更为严格。如将一个库中buffd0的Z端的max_fanout由4.0改为2.0的命令:
dc_shell> set_addribute find(pin, ex25/BUFFDO/Z) max_fanout 2.0
上述的命令可以写在synopsys-dc.setup文件中。
(单元的延时)
在一个单元的综合库中,最核心的是对时序和功耗的描述。一个单元的延时跟以下因素有关:
器件内部固有的延时、输入转换时间(也称为输入上升/下降时间)、负载(驱动的负载及连线)、温度、电压、制程变化。
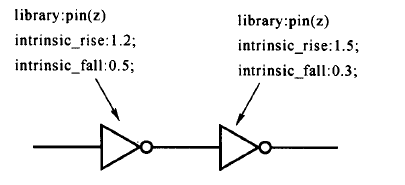
前三个因素是由电路本身的特性所决定的,后三个因素是由环境决定的。在实际电路中,输入转换时间、负载与连接单元的电路有关,所以我们只需要列出在不同的输入转换时间、不同的负载下单元的延时就可以了。这个延时包括器件的内部固有延时。此外,利用前面提到K缩放因子,将温度、电压、制程的影响也考虑进来。如下面的这个反相器单元,它的延时就可以通过输入转换时间和负载决定:
说到单元的延时,不得不说计算单元延时的模型。
Synopsys支持的延时模型包括:CMOS通用延时模型、CMOS分段线性延时模型和CMOS非线性延时查找表模型(Nonlinear Delay Model)。前两种模型精度较差,已经被淘汰,主要用非线性延时模型。下面进行解释非线性延时模型。
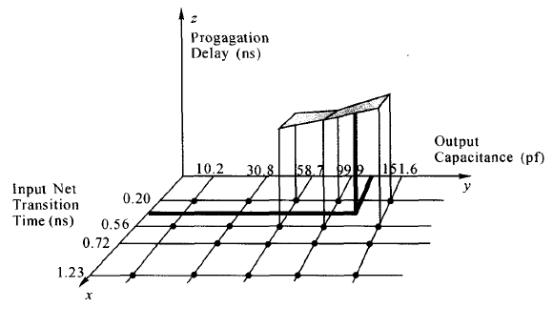
非线性延时模型也称为二维非线性延时模型。在该模型中,用二维列表的形式给出单元在特定的输入转换时间、输出负载下的延迟(包括单元的延时和单元的输出转换时间):

单元的输出转换时间又成为其驱动的下级单入的输ru转换时间。库中每个单元有两个NLDM表。上面的图中,当输出负载和输入转换时间为0.05 pF和0.5 ns时,从表中可查出单元的延迟为0.23 ns,输出转换时间为0.30 ns 。
对于在范围之内的点,可以用插值的方法得到;对于在范围之外的点,可以用外推的方法得到。线性插值如下图所示:
计算延时的公式为:
Z=A+BXX+CXY+DXXXY
其中,Z代表单元的延时,A, B, C, D是系数,X为输出节点电容,Y为输入转换时间。
输入的上升、下降时间是由上一级输出的上升、下降时间得到的。输出节点的电容可以由负载的输入引脚电容及连线负载计算得到。在综合时,使用导线负载表可以预测导线负载。导线负载模型在综合库中进行了定义。当然,用户也可以自己生成连线负载模型。该模型也是用查找表的方式,列出在不同负载下的平均连线延迟。在布局之后,可以得到更为精确的导线长度。在布线后,可以得到最确切的导线长度。可以用该导线负载来计算最终的延时,以便进行静态时序分析与时序计算。
使用线性插值的举例:一个标准单元的延迟查找表如下图所示:
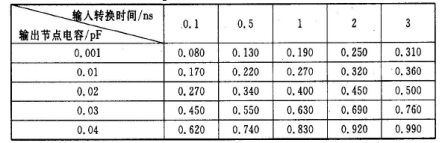
在查找表中,根据不同的输入转换时间和输出节点电容,列出了标准单元的延时。例如,当输入节点的转换时间为0.1 ns,输出负载为0.01pF时,单元的延时为0.17 ns。如果单元的输入转换时间为0.2 ns,输出节点电容为0.002 pF,则从表中无法直接查找到延时,需要通过线性插值的方法来求得该值:
计算延时的第一步,是求出延时公式中的系数A, B, C, D,然后根据实际的输入转换时间和输出电容求出实际的延时。
假设该单元的输入转换时间为0.2(位于查找表的第1列与第2列之间),输出节点电容为0.003(位于查找表的第1行与第2行之间),这样,我们将查找表中的相应的4值代入延时公式,可得:
0 .080=A+B*0.1 +C *0.001 +D*0.1*0.001;
0 .130=A+B * 0 .5+C * 0.001 +D*0.5*0.001;
0 .170=A+B * 0 .1+C*0.01 +D*0.1*0 .01
0 .220=A+B * 0.5+C*0.01 +D*0.5*0.01
求解这4个等式,可得 A=0 .057 52,B=0 .1248,C=9 .9998,D=0 .2。
接下来,我们将实际的节点电容、输入转换时间代入延时公式,可以得到这种情形下该单元的实际延时为:
Z=0 .5752+0.1248X0.003+9.9998 X 0.2+0.2X0.2X0.003 (ns)
单位为ns,输出转换时间、短路功耗的计算与此类似。
说明:利用DC中的report_power_calculation命令,可以显示出某一节点处energy的具体求解过程;利用DC中的report_delay_calculation命令,可以显示出某一节点处延迟或输出转换时间的具体求解过程。
前面对标准单元库的内容和结构有了一个概述,下面对一个反相器单元和一个寄存器单元进行详细解说。
·反相器的综合模型
综合库中主要给出了各端口的功能、电容、功耗及延时等信息(不同的库模型信息种类可能不一样)。反相器的功耗主要分为两部分:静态功耗和动态功耗。 其中静态功耗是指泄漏功耗,动态功耗包括翻转时的短路功耗及节点电容的充放电所消耗的功耗。节点电容充放电消耗的功耗仅跟VDD、节点翻转率及节点电容有关。其中,VDD和节点电容是固定的,节点翻转率跟输入激励有关,需要通过仿真激励进行计算。因此,在综合库中,不列出充放电功耗。而短路功耗跟输入转换时间和节点电容有关,一般以查找表的形式给出(在综合库中,用internal_power表示)。
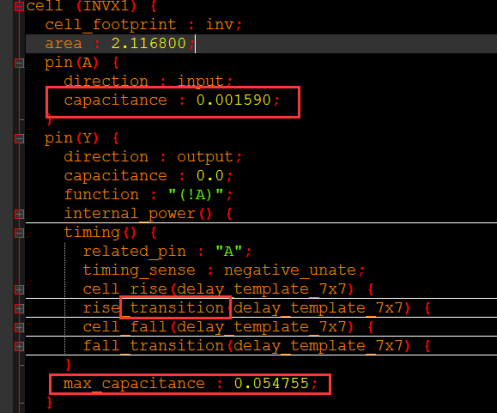
具体的反相器的综合模型如下所示:
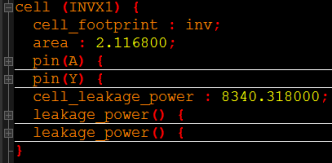

当然,上面看到的只是部分内容,有些内容折叠起来了比如输入引脚的等效负载、输出引脚的短路功耗等被折叠起来了,下面进行讲解:

引脚A表示反相器的输入(上图),展开后可以看到输入的引脚的等效负载,也就是等效电容的大小。
输出管脚Y有:
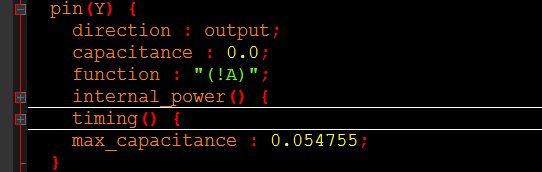
里面主要包含了引脚的功能(function)、短路功耗(internal_power)、时序信息(timing)、输出的最大负载(max_capacitance)等信息。
短路功耗信息(internal_power):
展开短路信息如下图所示:

短路功耗与A管脚相关联,也就是与A管脚有关系。
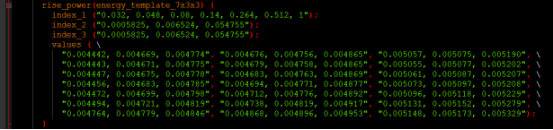
rise_power给出了Y从低到高时的短路功耗,功耗跟输入信号的转换时间(index_1)及节点电容(index_2)有关;根据不同的信息进行查表,表的值就是(value),7X7表示index_1是7,index_2也是7,因此value是7X7=49,如下图所示:
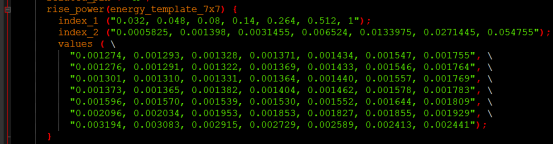
也给出了从高到低的短路功耗(fall_power),功耗跟输入信号的转换时间及节点电容有关;具体内容类似从低到高时的短路功耗,不再详述。
时序信息(timing):

主要包括相关引脚、时序敏感类型、单元延时、转换时间等。
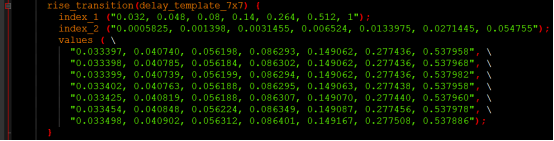
Cell_rise 给出了Y从低到高时单元的延时,延时跟输入转换时间和节点电容有关:
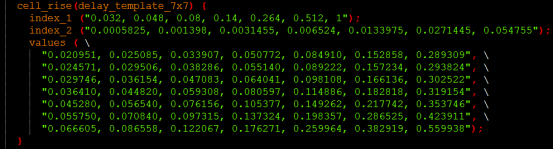
Rise_transition给出Y从低到高时输出的延时(transtion),跟输入转换时间和节点电容有关:
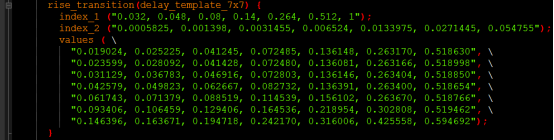
Cell_fall、fall_transition:则是对应Y从高到低时的单元延时和输出延时,也是跟输入转换时间和节点电容有关。
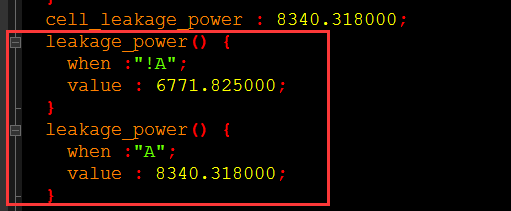
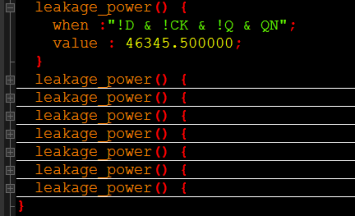
cell_leakage_power:单元的泄漏功耗
有时候,也给出在不同条件时的泄漏功耗(也就是查表的方式):
反相器作为组合逻辑最简单、最经典的模型,其综合库的模型内容就如上所示了,下面介绍时序逻辑的。
·寄存器单元的综合模型
寄存单元综合库模型主要包括以下内容:
· 单元面积;
·D端短路功耗;
·D端的建立时间约束和保持时间约束;
· 时钟引脚上的短路功耗;
· 时钟引脚上的最小脉宽要求;
· 输出端的短路功耗;
· 输出端的延时;
· 输出端的最大负载约束;
· 单元的泄漏功耗。
其综合库内容如下所示:

上面综合库的具体内容下面进行具体叙述:
D端口(引脚):
输入端口,主要包含输入的等效负载、短路功耗、时序信息。
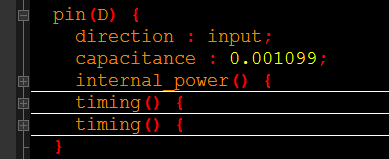
internal_power,D端消耗的短路功耗:

rise_power给出D端由低电平变到高电平时的短路功耗,跟输入转换时间有关,电容为定值:

fall-power则给出D端由高电平变到低电平时的短路功耗,跟输入转换时间有关,电容为定值。
Timing,时序信息:

D的时序信息与“CK”端口有关,Setup_rising表明是setup(建立时间)的时序信息。
rise-constraint:给出D端由低电平变到高电平时的setup约束,跟D端输入转换时间和时钟的转换时间有关:
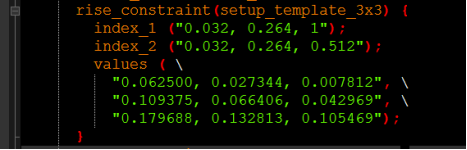
fall-constraint则给出D端由高电平变到低电平时的setup约束,跟输入转换时间和时钟的转换时间有关。
前面我们看到,有两个timing,一个既然是建立时间了,那么另外一个就是保持时间了:

rise-constraint:给出D端由低电平变到高电平时的hold约束,跟输入转换时间和时钟的转换时间有关:
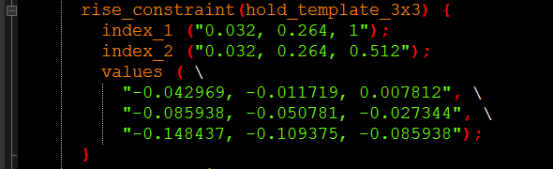
fall-constraint:给出D端由高电平变到低电平时的hold约束,跟输入转换时间和时钟的转换时间有关。
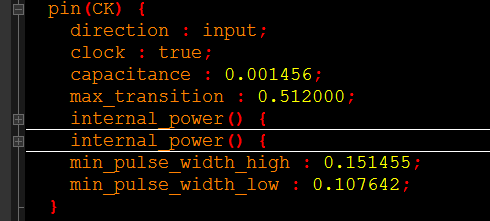
CK端口:
这个是时钟端口,主要给出了输入的负载、最大转换时间约束、短路电流、高低电平的最小脉宽要求,如下图所示。
Internal_power,短路功耗:
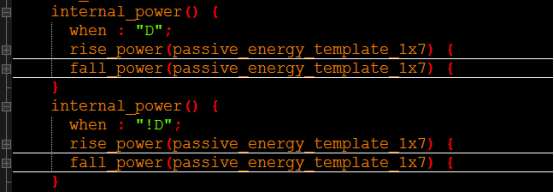
也是分为CK上升时跟下降时的短路功耗,与D端有关。
min_pulse_width_high、min_pulse_width_low :给出了时钟高低电平的最小脉宽要求。
ff:描述寄存器的功能。
Q端口:

主要描述Q的功能,短路功耗,时序信息,输出最大的负载电容。
Internal_power,短路功耗:

rise_power给出了输出端由低电平变到高电平时的短路功耗,跟输入转换时间、Q端负载及QN端负载有关:
fall_power则输出端由高电平变到低电平时的短路功耗,跟输入转换时间、Q端负载及QN端负载有关。
Timing,时序信息:

说明Q端口与CK的上升沿有关。
cell-rise给出Q端由低电平变到高电平时CK到Q的延时,跟输入转换时间和输出节点电容有关:

rise-transitio给出了Q端由低电平变到高电平时Q端转换时间,跟输入转换时间和输出节点电容有关:
cell-fall给出了Q端由高电平变到低电平时CK到Q的延时,跟输入转换时间和输出节点电容有关;
fall-transition给出了Q端由高电平变到低电平时Q端转换时间,跟输入转换时间和输出节点电容有关。
max_capacitance,则是最大输出负载电容约束。
QN管脚,跟Q管脚类似,不进行陈述了。
cell_leakage_power给出了默认单元漏电流大小。而下面的不同漏电流,则是根据端口信号处在不同状态时的漏电流大小:
注:对于有复位信号的寄存器,还有可能有下面的信息:
· 复位引脚上的短路功耗;
· 复位引脚上的最小脉宽要求;
· 复位引脚上的recovery/removal时序约束;
· 输出端的输出转换时间(相对于时钟);
· 输出端的输出转换时间(相对于异步复位信号);
· 输出端的延时(相对于异步复位信号);
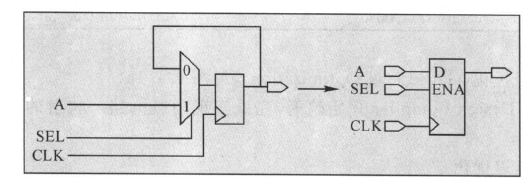
(2)DC的设计对象
在了解了综合库之后,下面介绍一下DC的设计对象,虽然这个设计对象相对于综合库没有那么重要,但是还是要了解一下的。
对于一个verilog代码模块,我们知道这是一个模块的名字是什么,这个模块的功能是什么,这个模块有哪些端口等等信息。但是对于DC来说,它不想我们那么理解,给它一个verilog模块,它把这个模块的内容当做设计对象(简称对象)来看。DC支持的对象和解释如下所示:
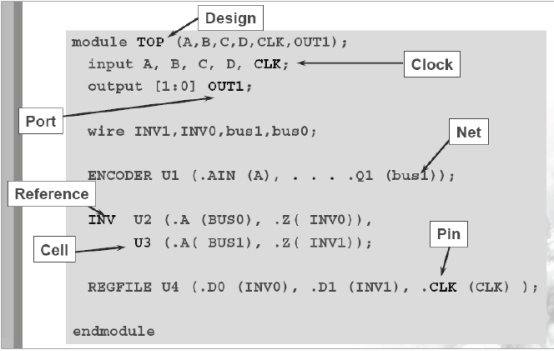
DC支持8中设计对象:
Design :具有某种或多种逻辑功能的电路描述;
Cell :设计的 instance;
Reference :cell 或 instance 在库中定义的名字;
Port :design 的输入、输出;
Pin :design 中 cell 的输入、输出;
Net :ports 和 pins 之间或 pins 之间的信号名;
Clock :被定义为时钟源的 pin 或 port;
Library :cell 的集合,如: starget_library,link_library;
在DC读入设计时候,可以通过下面命令查看这些对象:

Query:访问某一个对象,
Sizeof:查某一个(对象)集合的大小。
对象具有某些属性,比如:
端口(port)的属性有:方向、驱动单元、负载、最大电容约束等等
单元(cell)的属性有:层次化、不触碰 等待;
时钟的属性有:周期、抖动等;
写约束,就是通过对设计对象的属性进行约束,至于要约束什么,怎么约束,在后面进行介绍。
(3)Design Ware 库
DesignWare是Synopsys提供的知识产权(Intellectual Property,简称IP)库。IP库分成可综合IP库(synthesizable IP,SIP) ,验证IP库(Verification IP,VIP)和生产厂家库(foundry 1ibraries)。IP库中包含了各种不同类型的器件。这些器件可以用来设计和验证ASIC, SoC和FPGA。库中有如下的器件:
·积木块(Building Block)IP(数据通路、数据完整性、DSP和测试电路等等)。
·AMBA总线构造(Bus Fabric)、外围设备(Peripherals)和相应的验证IP。
·内存包(Memory portfolio)(内存控制器、内存BIST和内存模型等等)。
·通用总线和标准I/O接口(PCI Express,PCI-X,PCI和USB)的验证模型。
·由工业界最主要的明星IP供应商提供的微处理器(Microprocessor)和DSP核心。
·生产厂家库(Foundry Libraries)。
·板级验证IP<Board verification IP)。
·微控制器(Microcontrollers,如8051和6811)。
·等等
这里主要介绍集成在DC综合工具中的designware foundation库。所有的IP都是事先验证过的、可重复使用的、参数化的、可综合的,并且不受工艺的约束。
常用的designware foundation库单元如下所示:




使用IP库中的器件,可以用运算符号推论法(Operator Inferencing)或功能推论法(Functional Inferencing)。运算符号推论法是直接在设计中使用“+、一、*、>、一和<”等的运算符号。功能推论法是在设计中例化(instantiate) DesignWare中某种算术单元,例如直接指定用库中的DWF_ mult_ tc,DWF_ div_ uns和DWF_sqrt_tc单元。
由于DesignWare库中的所有器件都是事先验证过的,使用该IP库我们可以设计得更快,设计的质量更高,增加设计的生产力和设计的可重复使用性,减少设计的风险和技术的风险。对于每个运算符号,一般地说DesignWare库中会有多个结构(算法)来完成该运算。这样就允许DC在优化过程中评估速度/面积的折衷,选择最好的实现结果。对于一个给定的功能,如果有多个DesignWare的电路可以实现它,Design Compiler将会选择能最好满足设计约束的电路。此外使用DesignWare中的DW Foundation库是需要许可证的(license) , DW Foundation库提供了更好的设计质量(Quality of Result)。
使用DesignWare中IP的方法如下图所示:

Design Compile自动选择和优化算术器件。对于算术运算,我们并不需要在DC中指定标准的(基本的)综合库standard.sldb。标准的综合库standard.sldb包含内置的HDL运算符号,综合时DC会自动使用这个库。如果我们要使用性能更高的额外的IP库,例如DW_ foundation.sldb,我们必须指定这些库,如下所示:
#Specify for use during optimization
set synthetic_library dw_foundation.sldb
#Specify for cell resolution during link
lappend link_library $synthetic_library
本文的总结主要参考了《专用集成电路设计使用教程》、《数字IC系统设计》,局部图片来自这两本书。
-----------------------------------------------------------------
本文如果有错,欢迎留言更正;此外,转载请标明出处 http://www.cnblogs.com/IClearner/ ,作者:IC_learner
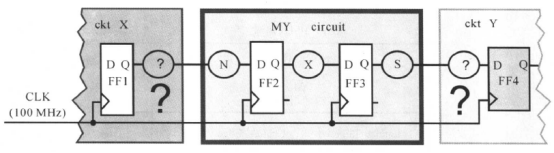
时序约束可以很复杂,这里我们先介绍基本的时序路径约束,复杂的时序约束我们将在后面进行介绍。
在本节的主要内容如下所示:
·时序路径和关键路径的介绍
·建立时间、保持时间简述
·时钟的约束(寄存器-寄存器之间的路径约束)
·输入延时的约束
·输出延时的约束
·组合逻辑的约束
·结合设计规格进行实战
RTL代码描述了电路的时序逻辑和组合逻辑,即RTL代码体现了电路的寄存器结构和数目、电路的拓扑结构、寄存器之间的组合逻辑功能以及寄存器与I/O端口之间的组合逻辑功能。但代码中并不包括电路的时间(路径的延时)和电路面积(门数)。综合工具现在不能很好地支持异步电路,甚至不支持异步电路,因此时序路径的约束主要是针对同步电路的,关于异步的电路的约束,后面也会进行相关的说明。
1、时序路径与关键路径
我们来看一下同步电路,常见的结构如下所示:

中间是我们设计的模块(芯片),对于同步电路,为了使电路能正常工作,即电路在我们规定的工作频率和工作环境下能功能正确地工作,我们需要对设计中的所有时序路径进行约束。那么时序路径是什么呢?下面进行解说:
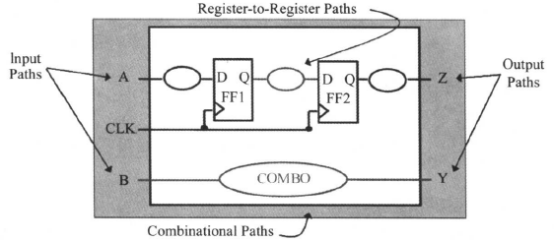
时序路径是一个点到点的数据通路, 数据沿着时序路径进行传递。每条时序路径有一个起点(Startpoint)和一个终点(Endpoint)。
起点定义为:
· 输入端口;
· 触发器或寄存器的时钟引脚。
终点定义为:
· 输出端口;
· 时序器件的除时钟引脚外的所有输人引脚。
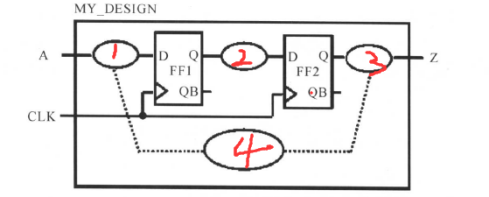
这样, 时序路径可以是输入端口到寄存器、 寄存器到寄存器、 寄存器到输出端口、 输入端口到输出端口。如下面这个电路中:
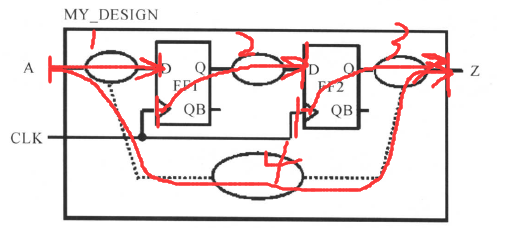
就有4条路径:
1:从输入端口A到FF1的D端;
2:从FF1的CLK端到FF2的D端;
3:从FF2的CLK端到输出端口out1;
4:从输入端口A到输出端口out1。
好看一点的图如下:
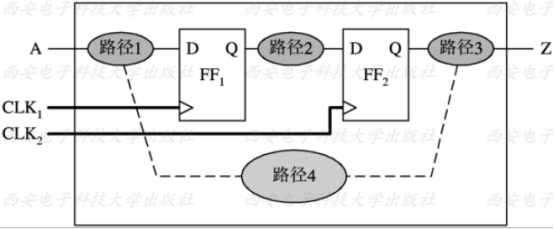
路径的特性是存在延时,也就是说,路径1、2、3、4都存在有延时,延时最长的一条路径称为关键路径。一般情况下,路径1、2、3是最常见的,路径4比较少见。
2、常见的时序路径约束
①建立时间、保存时间和亚稳态
在进行约束的时候,先了解触发器的三个概念:建立时间、保持时间以及亚稳态。这里只是简单地介绍一下,关于建立时间和保持时间的深入介绍,请查看我的博文:http://www.cnblogs.com/IClearner/p/6443539.html,关于亚稳态的深入介绍,请查看我的博文:http://www.cnblogs.com/IClearner/p/6475943.html
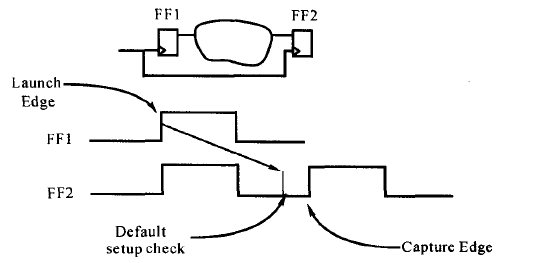
建立时间:时钟有效沿到来之前的某段时间内,数据必须稳定,否则触发器锁存不住数据,这段时间成为建立时间,用Tsetup或者Tsu表示。
保持时间:时钟有效沿到来之后的某段时间内,数据也必须稳定,否则触发器锁存不住数据,这段时间成为保持时间,用Thold或者Th表示。
如下图所示:
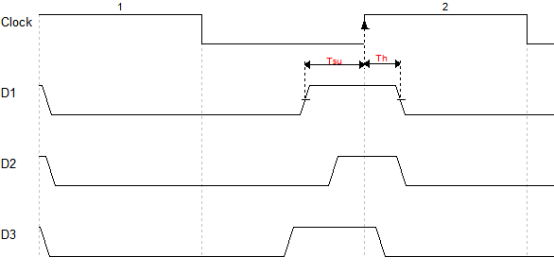
在第二个时钟上升沿的时候,要锁存住输入端D的高电平,D1是满足了建立时间和保持时间的情况;而D2则是建立时间没有满足,因此不能成功锁存住输入的高电平;D3保持时间不满足,也不能成功锁存输入的高电平。
亚稳态:每个触发器都有其规定的建立(setup)和保持(hold)时间参数,该参数存放在由半导体厂商所提供的工艺库中。假如触发器由时钟的上升沿触发,在这个时间参数内,输入信号是不允许发生变化的。否则在信号的建立或保持时间中对其采样,得到的结果是不可预知的,有可能是0或者1,即亚稳态。
有了这三个概念之后,我们可以对路径进行约束了。约束就是为了满足寄存器的建立时间(和保持时间),我们先对模块内的路径进行约束,也就是下面电路框图中的中间部分:
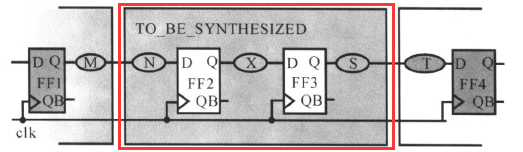
对于中间的部分路径,可以用前面的那个路径图来描述:
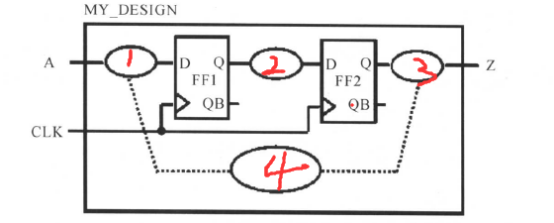
也就是主要约束这些类型的路径,本小节主要讲的就是这些路径的约束。
②路径2(寄存器到寄存器之间的路径)的约束:
我们先从寄存器到寄存器之间的路径2开始;前面说到了,为什么要约束时序路径,是为了满足寄存器的建立时间和保持时间。对于路径2,数据从FF1的D端口传输到FF2的D端口,主要需要经历触发器的翻转时间/转换延时、寄存器与寄存器之间的组合逻辑延时、连线延时这些种延时。因为数据是随着时钟的节拍一拍一拍往后传的,因此这里的寄存器与寄存器之间的路径约束,就是对时钟的建模,或者是说对时钟的约束。下面进行说明:
为了满足FF2建立时间的要求,也就是数据经过上面的延时(触发器的翻转时间/转换延时、寄存器与寄存器之间的组合逻辑延时、连线延时)之后到达FF2的D端的时间再加上FF2的建立时间,需要要小于时钟周期;也就是说,你的那些延时不能过大,延时一旦过大,数据可能就不满足建立时间的关系,甚至还更新不了。举个例子说:
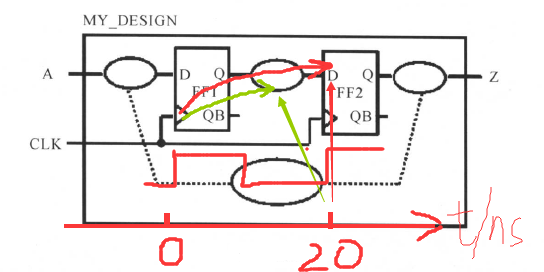
现在的节拍(0ns这一时刻)到来后,数据(比如说是一个高电平)从FF1的D端传来,经过组合逻辑,在下一个节拍(20ns这一时刻)的时候传到FF2的D端,更新FF2的数据(0ns时,FF2保存的是低电平),如红色箭头所示;但是由于延时太大,下一个节拍到来了(20ns到了),这个高电平还在还在组合逻辑那里,如绿色箭头所示,就导致了FF2的D端数据不能得到更新,或者不满足建立时间,由此可能引起锁存错误。当对时钟进行建模之后,拍长也就决定了,也就是那些延时(触发器的翻转时间/转换延时、寄存器与寄存器之间的组合逻辑延时、连线延时)最大是多少也就知道了,通过对时钟进行建模,也就是通过对寄存器与寄存之间的路径进行约束,DC就知道了这条路径运行的最大延时,就会选择合适的单元来满足这些延时的约束,如果DC选来选去,发现最牛逼的单元得到的电路延时还是很大,无法满足FF2的建立时间要求,DC就会报错。这个时候,你就要进行修改设计了(比如修改约束或者修改代码)。
为了满足FF2的保持时间,也就是数据经过上面的延时(触发器的翻转时间/转换延时、寄存器与寄存器之间的组合逻辑延时、连线延时)之后到达FF2的D端的时间,不能小于某个值。也就是说,这些延时也不能太小。举个极端的例子说,在0ns的时候,触发器有效沿到来,FF1和FF2都要更新下数据,FF1准备锁存高电平,FF2准备锁存低电平;由于FF1反应很快,电路延时很小,FF1寄存住的高电平很快就会传到FF2的D端口,高电平就会冲掉FF2要锁存的低电平(也就是FF2的D端口低电平还没有稳定,违反了保持时间),也就是说会导致低电平对FF2的保持时间不能得到满足,导致FF2更新数据失败,要锁存住的低电平可能就产生亚稳态。因此就有传输延时需要大于FF2的保持时间。此外,我们由此也可以知道,保持时间的分析比建立时间的分析提前一个时钟周期沿,也就是说在0ns时候传输数据,建立时间是在下一个时钟上升沿(20ns时刻)进行检查FF2的D端口数据是否稳定(若不稳定,就违反了建立时间),而保持时间是在发送数据的同一时刻(也就是0ns时刻)检查FF2的D端口数据是否稳定(如果不稳定,就违反了保持时间);关于保持时间的分析比建立时间的分析提前一个时钟周期沿这一点需要注意。
然而,保持时间一般是能够满足的,也就是传输延时一般是大于触发器的保持时间的,即使满足不了,在后端版图设计的时候,也可以有修改措施(比如路径加缓冲器增加延时)。因此我们在约束的时候,我们一般不关注保持时间,而是注重建立时间。
经过上面一大堆的废话,相信大家已经对这个约束过程有一定的了解了,下面进行概括一下,并进行时钟建模。
通过上面的讲解,我们知道,一般情况下,如果寄存器和寄存器之间组合电路的延迟大于Clock_cycle-Tsu(Clock_cycle是时钟周期,Tsu是触发器的建立时间),电路的功能会不正确,将不能正常工作。如果已知电路的时钟工作频率,就知道了寄存器和寄存器之间组合电路的最大时延,如下图所示:
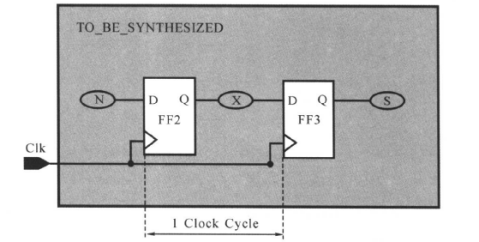
图中路径X的最大时延应满足下列关系:

Tclk-Q是FF2的从引脚CLK到引脚Q的延时,Tsetup是FF3的建立时间,这两个参数都由工艺库提供。总结完成之后,下面对时钟进行建模,也就是寄存器到寄存器之间的路径进行约束,时钟的建模是比较复杂的,因此先一步一步地讲解,最后给出约束脚本。
定义时钟时钟的命令为:create_clock。假设时钟周期为10ns,定义时钟的命令就是:
create_clock -period 10 [get_ports clk]
对于的时钟波形为:
定义时钟时(虚拟时钟除外,虚拟时钟在后面说),我们必须定义时钟周期(也就是-period这个选项)和时钟源(端口或引脚)(也就是设计中的clk),也可以加上一些可选项(option)来定义时钟的占空因数(duty cycle),偏移(offset/skew)和时钟名( clock name),我们可以通过man create_clock 来查看命令的相关选项。
一旦定义了时钟,对于寄存器之间的路径,我们已经做了约束。我们可以用report_clock命令来查看所定义的时钟以及其属性。如果我们需要使用时钟的两个沿(上升沿和下降沿),时钟的占空因数将影响时序的约束。
然而单单定义一个时钟周期进行约束寄存器与寄存器之间的路径很显然是过于理想的,需要再添加其他的时钟属性,在添加之前,需要知道时钟的偏移(skew)、抖动(jitter)、转换时间(transition)、延时(latency)这几个概念或者这几个时钟的属性,这些属性请查看我的另一篇博文:
http://www.cnblogs.com/IClearner/p/6440488.html
该博文详细介绍了时钟的建模,也就是路径2的约束。
③路径1(输入端口到寄存器D端)的约束:

这里讨论的是模块前后使用的是同一个时钟CLK,如下图所示,至于使用不同的时钟(比如前面的模块是ClkA而不是Clk,那么约束就不一样了)放在后面说。

在上图中,在Clk时钟上升沿,通过外部电路的寄存器FF1发送数据经过输人端口A传输到要综合的电路,在下一个时钟的上升沿被内部寄存器FF2接收。它们之间的时序关系如下图所示:
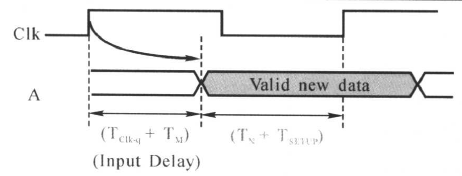
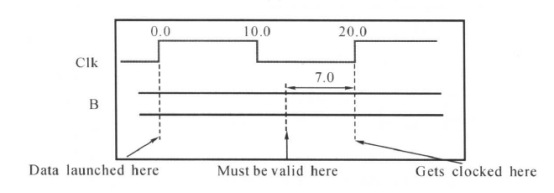
对于我们要综合的模块,DC综合输入的组合逻辑,也就是上面的电路N,得到它的延时是Tn,但是这个Tn是否满足的要求(比如说满足触发器的建立时间)呢?在进行约束之前,DC是不知道的,因此我们通过约束这条路径,也就是告诉DC外部的延时(包括寄存器翻转延时和组合逻辑、线网的传输延时)是多少,比如说是Tclk-q+Tm,在约束了时钟之后,DC就会计算这条路径留给电路N的延时是多少,也就是Tclk-q+Tm。然后DC就拿Tclk -(Tclk-q+Tm)和Tn+Tsetup相比较,看Tclk -(Tclk-q+Tm)是否比Tn+Tsetup大,也就是看综合得到的电路N的延时Tn是不是过大,如果Tn太大,大于Tclk -(Tclk-q+Tm),那么DC就会进行优化,以减少延时。如果延时还是太大,DC就会报错。因此我们要进行输入端口的约束,告诉外部电路的延时是多少,以便DC约束输入的组合逻辑。
如果我们已知输入端口的外部电路的延迟(假设为4 ns,包括翻转延时和外部的逻辑延时),就可以很容易地计算出留给综合电路输入端到寄存器N的最大允许延迟:

DC中,用get_input_delay命令约束输人路径的延迟:
set_input_delay -max 4 -clock CLK [get_ports A]
我们指定外部逻辑用了多少时间,DC计算还有多少时间留给内部逻辑。在这条命令中,外部逻辑用了4 ns,对于时钟周期为10 ns的电路,内部逻辑的最大延迟为10 - 4 - Tsetup = 6 。
例如,对于下面的电路:

输入端口延时的约束如下所示:
create_clock -period 20 [get-ports Clk]
set_input_delay -max 7.4 -clock Clk [get-ports A]
对应的时序关系图如下所示:
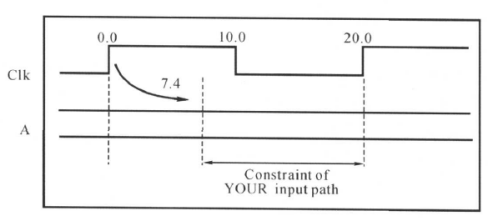
如果触发器U1的建立时间为1ns,则N逻辑允许的最大延迟为:
20 - 7 .4 - 1 = 11 .6 ns
换言之:如果N逻辑允许的最大逻辑为11.6ns,那么可以得到外部输入最大的延时就是20-11.6-1=7.4ns.
上面是没有考虑不确定因素情况,当考虑不确定因素时,则有:
当有抖动和偏移的时候(假设不确定时间为U),如果触发器U1的建立时间为1ns,外部输入延时为D(包括前级寄存器翻转和组合逻辑的延时),则N逻辑允许的最大延迟S为:
20-D-U-1=S,同样可以得到外部输入的延时为:20-U-1-S=D
当输入的组合逻辑有多个输入端口时,如下图所示:
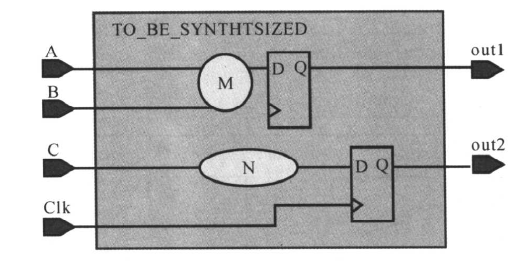
则可以用下面命令对除时钟以外的所有输人端口设置约束:
set_input_delay 3.5 -clock Clk -max [remove_from_collection [all_ inputs ] [get_ports Clk] ]
remove_from_collection [all_inputs] [get_ports Clk]”;#命令表示从所有的输入端口中除掉时钟Clk。
如果要移掉多个时钟,用下面的命令:
Remove_from_collection [all_inputs] [get_ports "Clk1 Clk2"]
④路径3(寄存器到输出端口)的约束:
在了解了路径1的约束直接之后,路径3的约束就变得容易理解了,路径3与外部输出电路的的电路图如下所示:
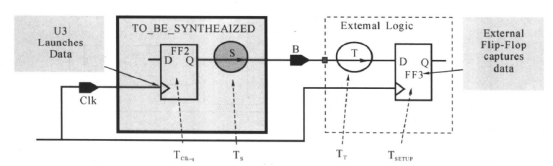
clk时钟上升沿通过内部电路的寄存器FF2发送数据经要综合的电路S,到达输出端口B,在下一个时钟的上升沿被到达外部寄存器的FF2接收。他们之间的时序关系如下图所示,我们要要约束的的组合路径电路S的延时,要DC计算它的延时是否能够满足时序关系,就要告诉DC外部输出的延时大概是多少:
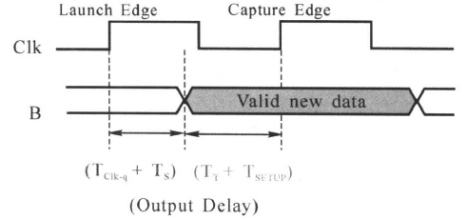
当我们已知外部电路的延迟(假设为5.4 ns),就可以很容易地计算出留给要综合电路输出端口的最大延迟,如下图所示:
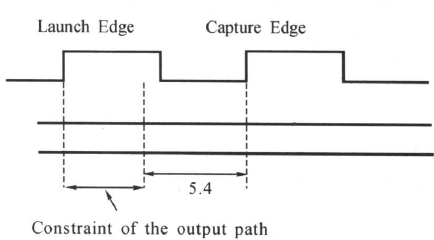
DC中,用set_output_delay命令约束输出路径的延迟,对于上面的电路图,有:
set_output_delay -max 5. 4 -clock Clk [get_ports B]
我们指定外部逻辑用了多少时间,DC将会计算还有多少时间留给内部逻辑。举个例子说,对于下面的这个电路模型:

寄存器到输出端口的时序路径约束为:
create_clock -period 20 [get_ports Clk]
set_output_delay -max 7.0 -clock Clk [get_ports B]
对应的时序关系图如下所示:
如果U3的Tclk-q = 1. 0ns,则S逻辑允许的最大延迟为:
20 - 7 .0 - 1=12 ns,也就是说如果S逻辑到最终的延时大于12ns,那么这条时序路径就会违规,DC就会报错。
上面是没有考虑抖动和偏移的,内部延时为S(包括clk-q和组合逻辑延时),外部输出延时为X(包括外部组合逻辑和后级寄存器的建立时间),时钟周期为T,那么就有:
T-S=X,知道了最大的内部延时S,就可以算出输出外部允许的最大延时X
当考虑抖动偏移等组成的uncertainty因素时,假设不确定时间为Y,那么就有:
T-Y-S=X,因此外部输出延时X,可以直接得到,也可以通过内部延时间S(和不确定时间Y)接计算得出X。
在这里说一下关于输入路径延时和输出路径延时的一些实际情况。 进行SOC设计时,由于电路比较大,需要对设计进行划分,在一个设计团队中,每个设计者负责一个或几个模块。设计者往往并不知道每个模块的外部输入延迟和/或外部输出的建立要求(这些要求或许在设计规格书里面写有,或许没有,当没有的时候设计者就不知道了),如下图所示:
这时,我们可以通过建立时间预算(Time Budget),为输入/输出端口设置时序的约束,也就是先预置这些延时,大家先商量好(或者设计规格书声明好)。但是预置多少才合适呢?就有下面的基本原则了:
DC要求我们对所有的时间路径作约束,而不应该在综合时还留有未加约束的路径。我们可以假设输人和输出的内部电路仅仅用了时钟周期的40%。如果设计中所有的模块都按这种假定设置对输人/输出进行约束,将还有20%时钟周期的时间作为富余量( Margin),富余量中包括寄存器FF1的延迟和FF2的建立时间,即:富余量=20%时钟周期 - Tclk-q - Tsetup,如下图所示:
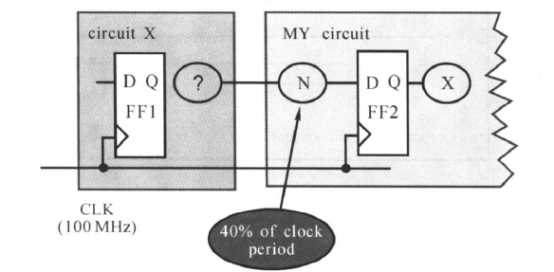
举个例子说,对于前面的电路,就要按照这么一个比例进行设置:
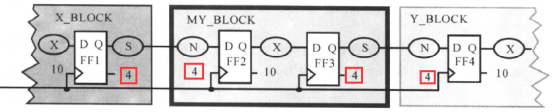
对应的约束为:
create_clock -period 10 [get-ports CLK]
set_input_delay -max 6 -clock CLK [all_inputs]
remove_input_delay [get ports CLK] ;#时钟不需要输入延迟的约束
set_output_delay -max 6 -clock CLK [all-outputs]
如果设计中的模块以寄存器的输出进行划分,时间预算将变得较简单,如下图所示:
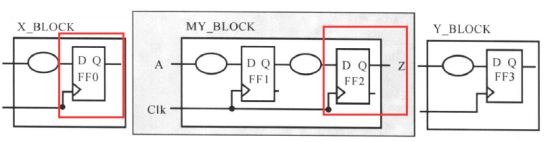
时间预算的约束为:
create_clock -period 10 [get-ports CLK]
set_input_delay -max $Tclk-q -clock CLK [all_inputs]
remove_input_delay [get ports CLK] ;#时钟不需要输入延迟的约束
set_output_delay -max [expr 10-$Tclk-q] -clock CLK [all-outputs]
⑤路径4的约束
路径4是组合逻辑的路径,组合逻辑的约束可能需要虚拟时钟的概念。组合逻辑可能有两种中情况,一种是前面电路中的路径4:
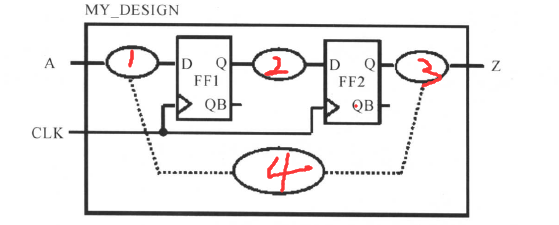
模块里面有输入端口到输出端口的组合逻辑外,也有时序逻辑,也就是模块里面有时钟,那么就可以对于路径4,就下面的电路模型进行约束:

组合逻辑部分F的延时Tf就等于时钟周期T-Tinput_delay-Toutput_delay,时钟周期减去两端,就得到了中间的延时约束了,对于上面的模型,可以这样约束为:
set_input_delay 0.4 -clock CLK -add_delay [get_ports B]
set_output_delay 0.2 -clock CLK -add_delay [get_ports D]
set_max_delay $CLK_PERIOD -from [get_ports B] -to [get_ports D]
当然,最后一句的约束可有可无。对于多时钟的同步约束,只需要修改相应的延时和时钟就可以了,可以参考前面的多时钟同步时序约束那里。
当考虑有不确定因素时,假设F的延时是F,外部输入延时为E(clk-q+组合逻辑延时),外部输出延时为G(组合逻辑延时+后级寄存器建立时间),不确定时间为U,时间周期为T,则有(最大频率下):
T - F -E-U = G
另外一种是纯的组合逻辑,模块内部没有时钟:
这种时钟需要用到虚拟时钟的概念,后面介绍有虚拟时钟的约束时,再进行说明。
3、实战
首先设计的模块如下所示:
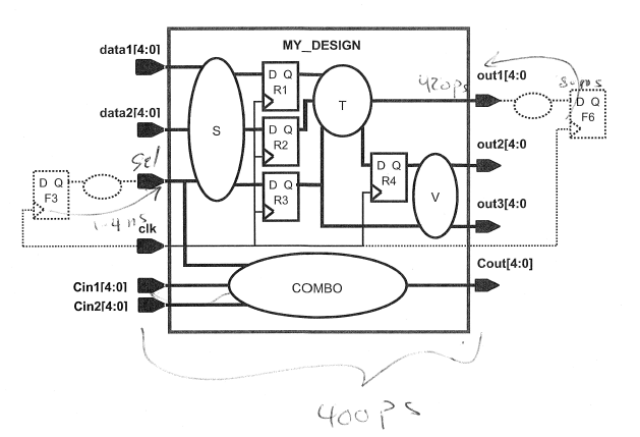
设计(约束)规格书如下所示:
(时钟的定义)

(寄存器建立时间定义)

(输入输出端口的延时定义)
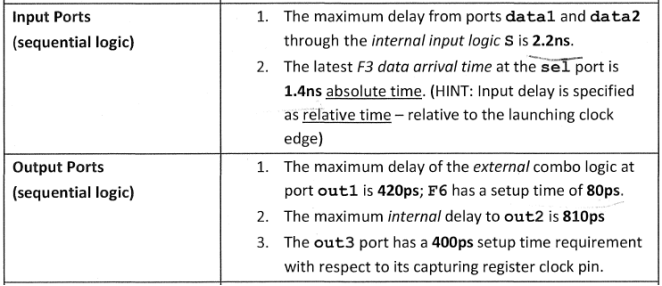
(组合逻辑的定义)

上面的规格定义用来给我们进行时序约束使用,现在实践开始。
·创建.synopsys_dc.setup文件,设置好DC的启动环境
-->common_setup.tcl文件:
由于这里有物理库,因此可以使用DC的拓扑模式进行启动。
-->dc_setup.tcl文件:
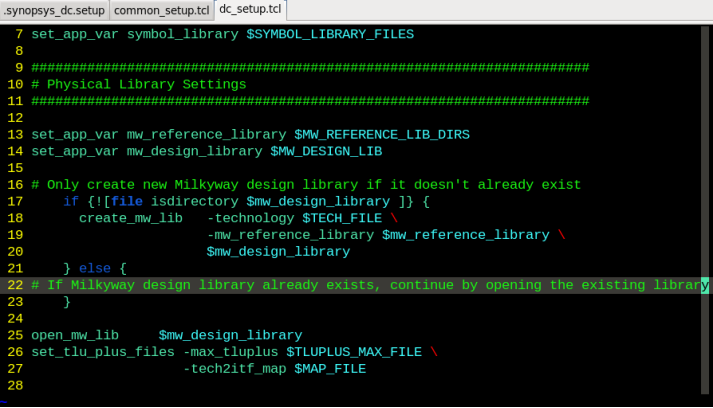
-->.synopsys_dc.setup文件:

-------------------------------------这一步时间不够下可以忽略------------------
·启动DC,查看target_library的信息
-->启动的时候,我们使用管道开关,把DC的启动信息保存到start_report.log里面(dc_shell -topo是DC的启动命令,启动时产生的信息,通过 | tee -i 流入start_report.log文件中):

(我们也可以通过启动gui界面进行输入命令,也可以在shell中输入命令)
-->由于我们仅仅是需要查看target_library库的信息,因此我们只需要读入库:read_db sc_max.db
-->然后我们查看与这个库相关联的工艺库:list_libs,结果为:
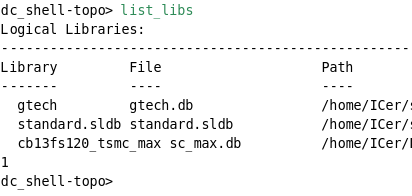
我们可以看到,sc_max.db是target_library的的文件名称,而target_library的库名字是cb13fs120_tsmc_max
-->接着我们查看库信息:

这里我们使用重定向的命令,将报告的结果保存到哦lib.rpt这个文件中。redirect是重定向的命令,-file是将命令产生信息保存到文件中,lib.rpt是要保存信息到文件,后面的{}中存放的是要执行的命令。
然后在终端读取相应库的单位信息,时序单位为ns,电容单位为pf
------------------------------------------------------------------------------------------------
·创建约束
在完成启动文件的书写之后,我就需要根据设计规格书,进行书写约束了
-->时钟的约束(寄存器和寄存器之间的路径约束):
1.时钟频率为333.33MHz,因此时钟周期就是3ns:
create_clock -period 3.0 [get_ports clk]
2.时钟源到时钟端口的(最大)延时即source latency是0.7ns
set_clock_latency -source -max 0.7 [get_clocks clk]
3.时钟端口到寄存器的时钟端口延时即network latency为0.3ns有0.03ns的时钟偏移:
set_clock_latency -max 0.3 [get_clocks clk]
4.时钟周期有0.04ns的抖动
5.需要为时钟周期留0.05ns的建立时间余量
这里我们就要设置不确定因素了,由于设计规格声明是对建立时间留余量,因此我们主要考虑建立时间的不确定因素:
首先是时钟偏移为±30ps,则有可能是前级时钟往后移30ps,同时本级时钟往前移30ps,对于建立时间偏移的不确定因素为30+30 =60ps;
然后是时钟抖动,前级的时钟抖动影响不到本级,因此只需要考虑本级的时钟抖动,由于是考虑建立时间,因此考虑本级时钟往前抖40ps,即对于建立时间抖动的不确定因素为40ps;
最后是要留50ps的建立时间不确定余量;
因此对于建立时间,总的不确定时间为60+40+50=150ps=0.15ns:
set_clock_uncertainty -setup 0.15 [get_clocks clk]
6.时钟转换时间为0.12ns:
set_clock_transition 0.12 [get_clocks clk]
-->输入延迟约束(输入路径的约束):
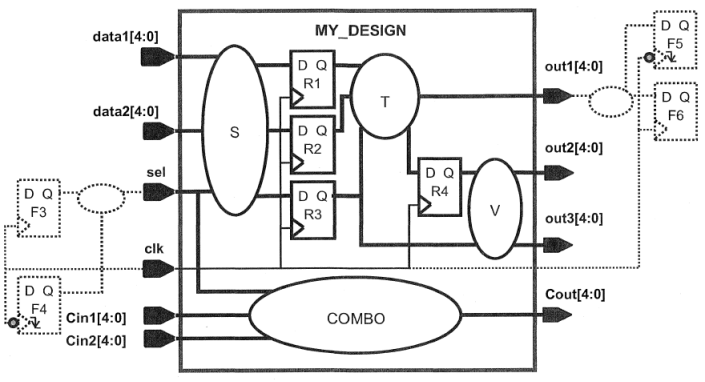
1.规定模块内data1和data2端口的逻辑S延时最大为2.2ns,并没有直接告诉外部逻辑的延时,因此我们需要计算:
外部最大的延时为:clock period - clock uncertainty - delay of S - register setup time = 3.0 - 0.15 - 2.2 - 0.2 = 0.45ns, 因此有:
set_input_delay -max 0.45 -clock clk [get_ports data*]
2.对于sel端口,由于明显地、直接说了从外部数据发送端(指的是F3的clk)到sel端口的latest(最大)绝对延时是1.4ns,也就是说,这个绝对延时包括了时钟的latency延时,而input_delay是不包括的,input_delay是相对时钟的前级逻辑延时,是不包括时钟的latency,那么就需要减去时钟的latency(包括source 和 network):
1.4ns-(700ps + 300ps) = 0.4ns,那么就有:
set_input_delay -max 0.4 -clock clk [get_ports sel]
-->输出延时约束(输出路径的约束):
1.直接告诉了在out1的外部组合逻辑的最大延时为0.42ns,后级触发器的建立时间为0.08ns,也就是外部延时为0.42+0.08=0.5ns:
set_output_delay -max 0.5 -clock clk [get_ports out1]
2.内部延时为810ns,应用前面的公式:时钟周期-内部延时(翻转与内部组合逻辑延时)-不确定时间=外部延时(外部组合逻辑+后级寄存器的建立时间),于是有:3-0.81-0.15=2.04ns,于是有:
set_output_delay -max 2.04 -clock clk [get_ports out2]
3.意思是外部延时只有后级寄存器的建立时间要求:
set_output_delay -max 0.4 -clock clk [get_ports out3]
-->组合逻辑的约束:
根据前面的公式可以得到:
3-0.15-输入延时-2.45=输出延时,于是可以得到:
输入延时+输出延时 = 0.4ns
由于设计规格没有规定这个比例,因此只要满足输入输出延时的关系满足上面的式子都可以,如果综合后有违规,我们后面可以再适当调整一下,设置为:
set_input_delay -max 0.3 -clock clk [get_ports Cin*]
set_output_delay -max 0.1 -clock clk [get_ports Cout]
-->检查语法:
·启动DC
(·读入设计前的检查)
·读入设计(和查看设计)
这里和流程一样。主要是read、current_design 、link、check_design,这里就不具体演示了。
·应用约束和查看约束
-->直接执行source scripts/MY_DESIGN.con进行应用约束
-->查看有没有缺失或者冲突的关键约束:
check_timing,返回值为1,表示执行成功。
-->验证时钟是否约束正确:
report_clock
report_clock -skew
report_port -verbose
-->保存约束好的设计:
write -format ddc -hier -out unmapped/MY_DESIGN.ddc
·综合
(简单的步骤跟流程一样)
·综合后检查(与优化)
(简单的步骤跟流程一样)
·保存综合后的设计
(简单的步骤跟流程一样)
---------------------------------------------
本文如果有错,欢迎留言更正;此外,转载请标明出处 http://www.cnblogs.com/IClearner/ ,作者:IC_learner
本文的主要内容是讲解(约束针对的是逻辑综合下的约束,而实战部分则是在DC的拓扑模式下进行):
·环境属性的约束
·设计规则的约束
·面积的约束
·实战(部分)环境属性的约束
1、工作环境属性约束
输入/输出端口及其驱动属性是设计规格的一部分,工作环境的约束,是对这个规格约束的一部分。
工作环境约束一方面是设置DC的工作环境,也就是DC要从在什么样的环境下对你的设计进行约束,举个例子,比如你的芯片要在恶劣的环境中进行工作,DC如果在优质的环境中对你的设计进行约束,你的芯片生产出来,就很有可能工作不了。因此一般就要告诉DC,使用恶劣的模型对设计进行约束。另一方面是为了保证电路的每一条时序路径延时计算的精确性,特别是输入/输出路径的精确性,单单靠外部的输入延时和输出延时的约束是不够,还要提供设计的环境属性。
这个约束可以看成是宏观的、整体的、外在的约束,约束的内容可以从下图看出:

·设置环境条件(set_operating_conditions):
用于描述制造工艺、工作电压与温度(PVT,process,voltage,temperature)这些周围环境对延时的影响。工艺库单元通常用“nominal”电压和温度来描述其默认的特性,例如:
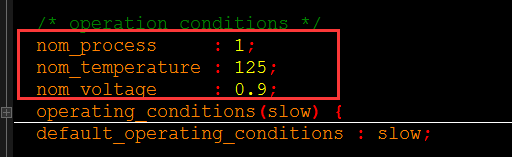
器件与线网上的延时在条件不同的时候呈线性变换。库文件中,包含对各种不同条件的具体描述,如slow,fast,typical等,对于芯片工作的最差、最好及典型的具体描述(具体见标准单元库那一节)。通过设置不同的操作条件,可以覆盖到各种不同的情况。
如果电路在不同于“nominal”电压和或温度的条件下工作,我们需要为设计设置工作条件(Operating Conditions),我们可以用set_operating_conditions命令把工作条件加入到设计上。综合时,原来按"nominal”环境计算出的单元延迟和连线延迟,将按工作条件作适当的比例调整,如下图为为延迟与工作条件的关系:
讲解完工作环境条件是什么之后,下面就介绍与它有关的常见的命令以及约束。工艺库中通常指定一个默认的工作条件.我们可以用:report_lib libname命令把厂商提供的所有工作条件列出来。
设置工作条件可用下面命令举例如下:
set_operating_conditions -max $OPERA_CONDITION -max_library $LIB_NAME
·设置线负载模型(set_wire_load_model):
在计算时序路径延迟时,除了需要知道门单元延迟外,还需要知道连线的延迟,如下图所示:
门单元的延迟一般用非线性延迟模型(non-linear delay model)算出。半导体厂商提供的工艺库中,有两个二维表格,根据门单元的输入转换时间和输出负载在表中找出门单元的延迟以及其输出转换时间。输出转换时间又作为下一级电路的输人转换时间。门单元的延迟在综合库那一节详细介绍。
连线的延迟目前一般用(连)线负载模型( Wire Load Model,简称WLM)估算。WLM是厂商根据多种已经生产出来芯片的统计结果,在同样的工艺下,计算出在某个设计规模范围内(例如门数为0~43478.00、门数为43478.00~86956.00,等等)负载扇出为1的连线的平均长度,负载扇出为2的连线的平均长度,负载扇出为3的连线的平均长度等等。WLM是根据连线的扇出进行估算连线的RC寄生参数,一般情况下,由半导体厂商建立。厂商根据已生产出来的其他设计统计出该工艺的连线寄生参数。半导体厂商提供的工艺库中包括了线负载模型。通常在一个综合库里面有多种线负载模型,不同的模型模拟不同规模的的模块内的线上负载情况(具体见综合库描述那一节)。用户也可以自己创建自己的线负载模型去更精确地模拟设计内的线上负载。连线负载模型的格式如下图所示(上),具体格式由工艺库决定(下):

关于线负载模型的更多内容,可以参考综合库/工艺库那一节。
线负载模型为DC提供统计性估算的线网负载信息,随后DC使用这些线网负载信息,以负载的大小为函数来模拟线上的延时(也就是设置这个约束是用来模拟线延时)。因此设置线负载模型。
如DC遇到连线的扇出大于模型中列出的最大扇出值,它将使用外推斜率(Extrapolation slope)来计算连线的长度。上例格式中,如果连线的扇出为7,而连线负载模型中最大扇出是5,连线的其长度计算如下:

讲完线负载模型是什么东西,为什么设置线负载模型约束之后,下面介绍与其相关的命令。
如果要查看工艺库中的WLM,可以使用命令:report_lib $lib_name,进行综合时,综合工具会默认根据设计面积和节点处的负载自动选择合适的连线负载模型,如果要关掉自动选择WLM,那么可以使用命令:
set auto_wire_load_selection false
然后手动选择线负载模型的命令是:
set_wire_load_model -name $WIRE_LOAD_MODEL -library $LIB_NAME
如果连线穿越层次边界,连接两个不同的模块,那么有三种方式对这种跨模块线连接的类型进行建模,set_wire_load_mode命令用于设置连线负载模型的模式。有三种模式供选择:top、segment和enclosed。三种模式的示意图如下所示:
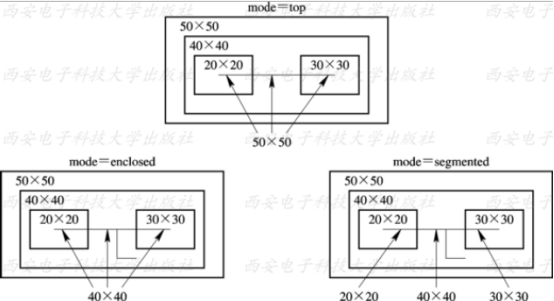

由图可见, 该设计的顶层设计(top)包括一个子模块, 该子模块又包括两个更小的模块。 顶层设计对应的连线负载模型为50×50; 子模块对应的连线负载模型为40×40;更小的两个模块对应的负载模型为20×20和30×30。
假设有一个连线贯穿两个小模块, 但没有超出子模块的范围。 对于这种连线, 在三种模式下, 所用的连线负载模型是不同的,下面是介绍:
比较悲观的形式:这时,top为顶层设计,电路的规模比SUB模块大,连线负载模型最悲观。在top模式下, 采用top层的连线负载模型, 即50×50;因此,连线的延迟最大。我们一般选用这种方式,命令如下:
set_wire_load_mode top
比较不悲观方式:用enclosed的方式选择WLM,该W LM对应的设计完全地包住这条连线,这时DC将选择SUB模块对应的连线负载模型。在enclosed模式下, 采用子模块的连线负载模型, 即40×40;因SUB模块比较TOP设计小,所以连线的延迟比较短(不悲观,就是连线延时小)。对应的命令为:
set_wire_load_mode enclosed
在segmented模式下, 位于两个小模块中的部分采用这两个小模块对应的连线负载模型, 中间部分采用子模块的连线负载模型。
驱动强度、电容负载这些约束是要经验的,一方面是对I/O口进行约束,属于I/O口的约束,为时序约束与时序分析提供了路径,更是为输入/输出路径延时约束的精确性提供保证;一方面是对I/O口对外的环境进行约束,可以算是属于环境约束,因此放在这里进行讲解。
·设置驱动强度(set_drive与set_driving_cell):
为input或者inout的端口设定驱动。Set_drive以电阻值为计量,0表示最大驱动强度,通常为时钟端口;而set_driving_cell则以模拟端口驱动的器件形式计量,说明输入端口是由一个真实的外部单元驱动。
为什么要需要为input或者inout的端口设定驱动?这是因为,对于输入端,为了精确计算输入电路的延时时间,DC需要知道到达输入端口的转换时间:
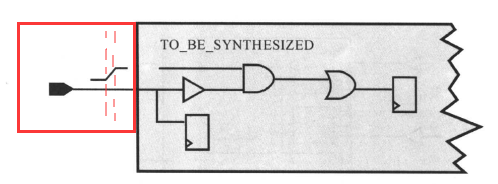
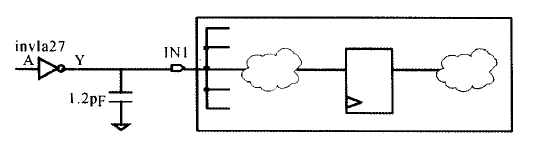
在默认情况下,DC假设输入端口上的外部信号转换时间是0 ,也就是从上升沿跳变到下降沿或者下降沿跳变到上升沿的时间是0,这是不符合实际情况的。通过设置驱动强度,就告诉DC这个设输入端口实际上是由一个真实的外部单元驱动的,不是理想的;DC就会计算输入信号的实际转换时间,仿佛指定某一个库单元正在驱动输入端,下面是输入端IN1 由FD1的输出引脚驱动的例子:
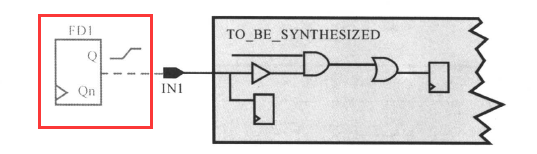
对应的约束可以这样写:
set_driving_cell -lib_cell FD1 -pin Q [get_potrs IN1]
如果不用开关选项“-pin",DC将使用所找到的第一只引脚(库中这个单元的第一个引脚,这个驱动引脚貌似是要选择输出的引脚)。
此外,除了通过这两种方式,还可以直接设置输入端口的转换时间,如下所示:
set_input_transition 时间 [get_ports 设计对象]
·设置电容负载(set_load与set_load load of):
明确说明端口(输入或输出)上的外部电容负载。对于输出端,为了精确地计算输出电路的延时时间,DC需要知道输出单元所驱动的总负载:
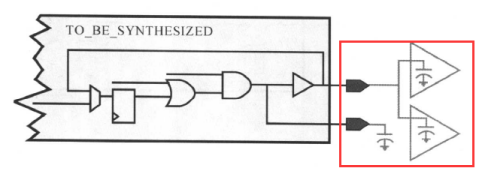
默认情况下,DC假设端口上的外部电容负载为0。我们可以指定电容负载为某些常数值,也可以通过用loacl_ of选项明确说明电容负载的值为工艺库中某一单元引脚的负载(一般是选择输入引脚):
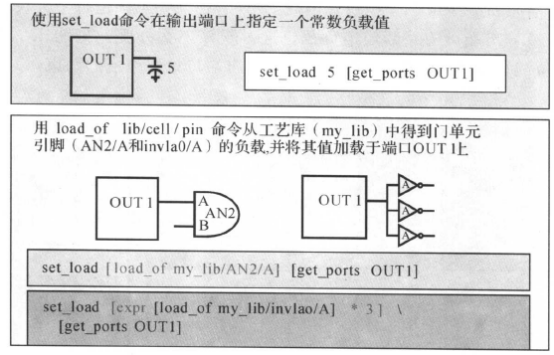
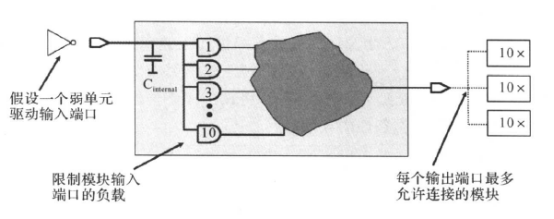
跟设计输入输出延时一样,设计者往往并不知道每个模块输入端口的外部驱动单元和/或输出端口的外部输出负载。因此我们要通过负载预算(Load Budget),为输入/输出端口设置环境的约束。产生负载的原则如下:
1.保守起见,假设输入端口为驱动能力弱的单元驱动(即转换时间长);
2.限制每一个输入端口的输入电容(负载);
3.估算输出端口的驱动模块数目。
例如:(只是举例)对于下面的电路图:
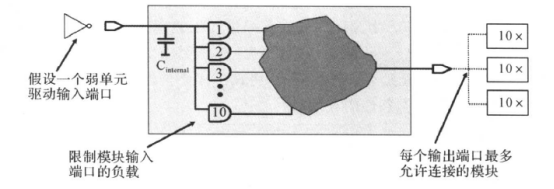
其规格为:模块输入端口驱动的负载不大于10个“AND2”门的输入引脚的负载,模块输出端口最多允许连接3模块,如果某个输出端需要连接多于3个模块,我们要在代码中复制该输端口。
对应的约束为:

环境约束举例如下所示:
语法中,设置(定义变量时),如上面的:
Set ALL_IN_EXCEPT_CLK [remove_from_collection [all_inputs] [get_ports “$CLK_NAME”]]中,后面的remove_from_collection是移除设计物集对象的意思,我们知道,DC可以将设计识别成多个对象,比如输入端口、输出端口等等,然后这个就是从all_inputs这个对象集合中,移除掉CLK_NAME这些代表的端口;如果命令之中有命令时,需要用[]来括起来。
然后是expr是表达式求值的意思,因为load_of取出了一个端口的负载值(因为哟load_of这个命令,即命令中有命令,因此需要加[]),这个值*10 是个表达式,因此用expr来指出求值,求值是一个命令,因此用[]括了起来。
上面中,LIB_NAME、WIRE_LOAD_MODEL、DRIVE_CELL 、DRIVE_PIN、OPERA_CONDITION这些变量的内容都不是随便定义的,需要根据综合库书写,下面进行解释,库的具体内容参考综合库那一节。
LIB_NAME:库的名字,这里使用的恶劣的情况:
WIRE_LOAD_MODEL:线负载模型,打开slow.lib这文件,可以找到各种线负载模型:
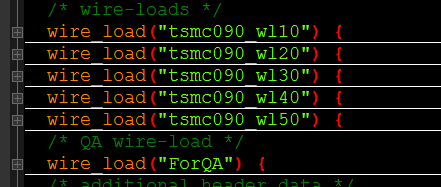
约束中选的是w150的。
DRIVE_CELL:驱动单元,也就是用来模拟驱动输入端的驱动单元,这要选择库中有的单元,比如反相器:
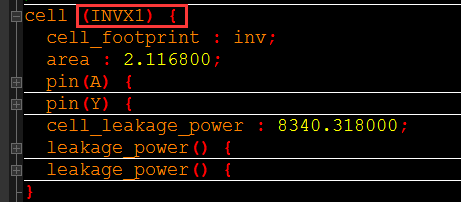
DRIVE_PIN:驱动管脚,为单元的输出管脚,也就是“Y”了。
OPERA_CONDITION:这个操作环境也是要填写库里面有的:
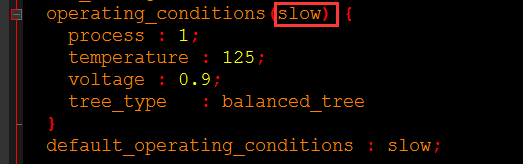
设置完这些变量之后,还设置了ALL_IN_EXCEPT_CLK和MAX_LOAD变量,其中ALL_IN_EXCEPT_CLK变量代表了除了时钟之外的输入管脚。MAX_LOAD变量就表示了最大的负载,代表的是库中某个单元的输入负载值。
最后面的就是设置工作环境了。
2、设置设计规则约束
set_max_transition、set_max_fanout、set_max_capacitance
主要是设置最大转换时间、最大扇出及最大负载电容要求,可以设置在输入端口、输出端口以及当前设计。举个前面的环境约束的例子说,比如我约束了输入端口的最大转换时间和负载,也约束输出最大扇出,如下图所示:
当综合和优化了,计算发现输入端口实际的转换时间比约束的大,或者负载比约束的大(模块输入端口驱动的负载大于10个“AND2”门的输入引脚的负载),或者检测到输出端口的扇出数比约束的要多(模块输出端口最多允许连接3模块,如果某个输出端需要连接多于3个模块),这时候就违背了设计规则,DC就会报错了。
半导体厂商在工艺库强加了设计规则。这些规则根据电容、转换时间和扇出(capacitance,transition和fanout)来约束有多少个单元可以相互联结。设计规则一般由半导体厂商提供,在使用工艺库中的逻辑单元时对其联结所强加的限制。例如,如果设计中一个逻辑单元的负载(其驱动的负载)大于库中给定的其最大负载电容(max_capacitance)值,半导体厂商将不能保证该电路能正常工作。我们只可以按照设计规则的约束或按照更严格的设计规则约束来设计电路,而不可以放松约束。Design Compiler在综合时使用加入缓冲器(buffering)和改变门单元的驱动能力(cell sizing)技术来满足设计规则的目标。
库单元的设计规则(design rule)一如下所示:
在约束工作环境的时候,调用了库中的一些单元(的引脚),就相当间接设置了设计规则约束,我们可以不必设置。
下面我们来详细叙述一下DC进行综合时设计规则约束:
DC在做综合时,把设计规则的优先级设置为最高。优先级的从高到低次序为:最大电容(max_capacitance)、最大转换时间(max_transition)、最大扇出(max_fanout).
·最大电容(maxcapacitance)的约束,例如对于下面的电路:
对应的最大的电容约束如下:
【1】set DRIVE_PIN TECH_LIB/invla27/Y
【2】set MAX_CAP [get_attribute $DRIVE_PIN max_capacitance]
【3】set CONSERVATIVE_ MAX_CAP [expr $MAX_CAP / 2.0]
【4】set_ max_ capacitance $CONSERVATIVE_ MAX_CAP [get_ports IN1]
约束的意思是:首先【1】处,我们选择使用综合库里面库单元的一个输出引脚作为设计中预期驱动器的最大允许电容负载,其值通过【2】得到,假设为3.5pf,也就是MAX_CAP = 3.6pf。然后通过【3】设置约束时使用的最大电容变量,除以2是在驱动器增加一些富余量使DC不会给它加满载。最后【4】就是设置输入引脚IN1的最大电容量为CONSERVATIVE_ MAX_CAP,也就是1.8pf。
当设置了输入端口的负载之后,也就是:
set_load 1.2 [ get_ ports IN1]
那么DC可以给输入端口 IN1 施加的最大内部负载是:1.8 - 1.2 = .06pf。
我们可以用“set_max_capacitance 3. 0 $ current_design”命令为整个设计中加入最大电容的设计规则。此处,用了3. 0为最大的电容值,设计时我们可以根据工艺库和电路的具体情况,选用合适的数值。要注意不要施加过度保守的约束,以免严重地限制DC对设计的优化。当然,如果库内定的值不够恰当或者过于乐观,我们可以手动设置,以控制设计的裕量。
·最大转换时间(max_transition)的设计约束,例如前面的电路,可以进行下面的最大转换时间约束:
#从工艺库找出设计中预期驱动器的最大允许转换时间,也就是最大转换时间可以像这个引脚这么大,假设其值为0.400ns。
set DRIVE_ PIN TECH_ LIB/invla27/Y
set MAX_TRANS [get_attribute $DRIVE_PIN max_transition]
#在实际驱动的时候,增加一些富余量使DC不会给它加满载,也就是实际上的转换时间不超过CONSERVATIVE_ MAX_TRANS,也就是0.200ns。
set CONSERVATIVE_ MAX_TRANS [expr $MAX_TRANS / 2.0}]
set_ max_transition $CONSERVATIVE_ MAX_ TRANS [get_ports IN1]
约束之后,DC考虑驱动单元的类型和它的外部负载, DC限制输入端口IN1的内部负载来满足的设计规则,也就满足你这个转换时间,让它不超过该0.2ns。
有时候我们可以在整个设计上施加最大转换时间的设计约束,以帮助防止可能在长连线上出现的慢(长)的转换时间,从而导致设计中出现特别长的延迟。施加最大转换时间的设计约束也可以约束单元输出端的转换时间以减少其功耗。我们可以用’set_max_transition 0. 4 $ current_design,命令在整个设计中加入最大转换时间的设计规则。此处,用了0. 4为最大转换时间值,设计时我们可以根据工艺库和电路的具体情况,选用合适的数值。要注意不要人为地加紧对整个设计的约束,以免限制DC对设计中真正关键器件的适当优化。
·最大扇出(max_fanout)的设计规则的约束,例如对于下面的电路:
用set_max_fanout命令为设计设置最大扇出的设计规则的约束,例如:
set_max_fanout 6 [get_ports IN1]
要注意set_max_fanout命令使用的是扇出负载(fanout_load),而不是绝对的扇出数目。端口的扇出负载之和必须小于最大扇出的设计规则的约束。进行上面的约束之后,DC在综合时会查看有没有违反规则,我们也可以自己查看有没有违反设计规则,用下面命令可以得到单元invla和invla27的扇出负载:
get_attribute TECH_LIB/invla1/A fanout_load --->比如说是0.25
get_attribute TECH_LIB/invla27/A fanout_load --->比如说是3.0
因此就有DC可以在端口IN1连接6/0.25=24个invla1单元,或在端口IN1连接6/3. 00=2个invla27单元。但是对于上面的电路,其IN1端口的扇出负载之和为:
3*fanout_load(invla1/A)+ 2*fanout_load(invla27/A)=(3 x 0.25)+(2x3.0)=6.75
因此,电路违反了最大扇出负载的设计规则约束。
与扇出有关的还有线负载模型,线负载模型根据连线的扇出数目来估算连线电阻和电容值。连线的扇出数目定义为单元输出引脚与其他单元的输入引脚之间连接的数目。与连线的扇出数目不同,扇出负载属性是附加在单元的输入端口,不同单元可以有不同的扇出负载属性。
我们可以用如下的命令限制整个设计的扇出负载:set_max_fanout 6 $current_design ,在对FPGA做综合,常常使用此命令。它也适用于ASIC的综合,特别是线负载模型和单元的输入负载不大精确时使用。
一些工艺库中,某些单元的引脚没有扇出负载属性。这时,DC会检查库中默认的扇出负载属性(default_fanout_load) 。如果库中没有默认的扇出负载属性,DC假设其值为“0",即这些单元的引脚不受扇出负载的设计规则约束。我们可以强制使端口的扇出数目为1,即只与一个单元连接,如果库中单元的扇出负载最小值为1. 0,用下面的命令加上扇出负载的设计规则约束:
set_max_fanout 1.0 [all_inputs]
如果库中单元的扇出负载最小值不为1. 0,我们需要先找出扇出负载最小的单元(假设为bufla1),计算出其扇出负载值,然后加上扇出负载的设计规则约束:
set SMALL_CELL TECH_LIB/bufla1/A
set SMALL_FOL [get_attribute $SMALL_CELL fanout_load]
#库中单元的扇出负载最小值为0. 5000
set_max_fanout $SMALL_FOL [all_inputs]
扇出负载值是用来表示单元输人引脚相对负载的数目,它并不表示真正的电容负载,而是个无量纲的数字。
如果我们所用的所有库单元扇出负载为“1",那么set_max_fanout 1. 0 [all_inputs]约束将强制所有的输人端口扇出数目为1,即它们只能与一个单元连接。否则,为了使输入端口只能与一个单元连接,我们要找出库中哪一个单元的扇出负载最小,在set_max_ fanout命令中使用这个值来保证在这个端口上只连接一个单元。如果单元上没有扇出负载属性并且库中本身也没有(默认)预设的扇出负载属性,那么把它设为1. 0是有意义和效用的。我们也可以在输出端口上指定扇出负载值。例如,假设一个内部单元驱动几个其他的单元并且也同时驱动一个输出端口。我们可以用set_ load命令来指定那个输出端口的实际电容负载。set_ load命令帮助DC在综合时遵从驱动单元的最大电容设计规则,但该命令并没有为驱动单元的扇出提供独立的约束。在输出端口使用set_ fanout_ load命令时,我们可以为输出端口建立额外的预期扇出负载模型,综合时DC同时也会使内部驱动单元的最大扇出遵守设计规则的要求。
可以使用下面命令report_constraint -all_violators查看是否违反设计规则。
3、面积约束
下面就是进行面积的约束,也就是告诉DC综合的电路面积要在多少以内。在介绍约束命令之前,先了解一下面积的单位。面积的单位可以是:
·2输入与非门(2-input-NAND-gate)
·晶体管数目(Transistors)
·平方微米(Square microns)
此外,我们往往看到一个芯片是多少多少门,这多少门的数字就是拿芯片的总面积,除以2输入与非门的面积得到的数值。用report_lib命令不可显示面积的单位,我们要询问半导体厂商面积的单位是什么。
如果不设置面积的约束,Design Compiler将做最小限度的面积优化。设置了面积的约束后,DC将在达到面积约束目标时退出的面积优化。如果设置面积的约束为“0" , DC将为面积做优化直到再继续优化也不能有大的效果。这时,DC将中止优化。注意,对于很大(如百万门电路)的设计,如将面积的约束设置为“0" , DC可能要花很长的时间为设计做面积优化。综合时,运行的时间很长。
在超深亚微米(deep sub-micro)工艺中,一般说来,面积并不是设计的主要目标,对设计的成本影响不大。因此,我们在初次优化时,可以不设置面积的约束。优化后,检查得到的设计面积,然后将其乘上一个百分数(例如8500),将其结果作为设计的面积约束。再为设计做增量编辑,运行“compile -inc”命令,为面积做较快的优化。这样做,既可以优化面积,又可以缩短运行时间。
最后我们用set_max_area命令为设计作面积的约束。例如:
set_max_area 10000
当设计不是很大的时候,根据上面的描述,我们就可以使用下面的命令进行面积约束:
set_max_area 0
让DC做最大的面积优化约束。
4、实战
由于种种原因,这里只有环境属性的约束的实战,其他的约束也可以通过上面的讲解和下面的这个实战进行设计。
首先,我们来看看设计约束规格:
(设计原理图)
(设计规范)
在前面一节的基本时序约束规范上加上下面的规范:

·DC启动环境的设置我们根据设计原理图和设计规范开始进行实践:
(跟上一节一样,这里不再重复)
·约束文件的编写
基本的时序路径约束和上一节一样,不进行改动,下面进行工作环境的约束:
-->输入端口的驱动设置:
1.要我们使用库里面的bufbd1来驱动除了clk和Cin*之外的所有输入端口:
这里是直接使用库里面的单元来驱动的,根据前面的讲解,我们很容易得到约束的命令为:
set_driving_cell -lib_cell bufbd1 -library cb13fs120_tsmc_max [remove_from_collection [all_inputs] [get_ports "clk Cin*"]]
(命令的格式为)set_driving_cell -lib_cell 单元的名字 -library 单元所在库的名字 要设置约束的对象
注意:当一条命令太长,要进行分割时,使用反斜杠\作为分隔符,且反斜杠后面不能加空格。
2.Cin*是芯片级的端口,需要加上120ps的最大转化时间,这是直接设置转换时间,因此可以这样约束:
set_input_transition 0.12 [get_ports Cin*]
-->输出负载的约束:
1.除了cout输出,其它输出驱动值都是库单元bufbd7的引脚I负载值的两倍,也就是用单元的端口进行约束,因此有:
set_load [expr 2 * {[load_of cb13fs120_tsmc_max/bufbd7/I]}] [get_ports out*]
2.cout驱动最大值为25pf的负载,因此可以这样设置:
set_load 0.025 [get_ports Cout*]
-->操作环境的设置:
由于用到了库里面的单元,我们还在最好设置一下操作环境,虽然DC可以从启动环境里面找到单元所在的位置库,但是我也要设置操作环境,如下所示:
set_operating_conditions -max cb13fs120_tsmc_max
下面的步骤跟前面的一样,这里就不展开描述了:
·启动DC,设计读入前的检查
·读入设计和检查设计
·执行约束和检查约束
·进行综合
...
------------------------------------
本文如果有错,欢迎留言更正;此外,转载请标明出处 http://www.cnblogs.com/IClearner/ ,作者:IC_learner
对进行时序路径、工作环境、设计规则等进行约束完成之后,DC就可以进行综合、优化时序了,DC的优化步骤将在下面进行讲解。然而,当普通模式下不能进行优化的,就需要我们进行编写脚本来改进DC的优化来达到时序要求。理论部分以逻辑综合为主,不涉及物理库信息。在实战部分,我们将在DC的拓扑模式下进行。(本文主要参考虞希清的《专用集成电路设计实用教程》来写的总结整理与实验拓展)主要内容有:
·DC的逻辑综合及优化过程
·时序优化及方法
·实战
1.DC的综合优化阶段
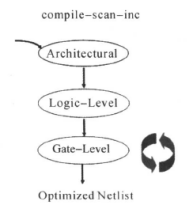
我们使用compile命令就可以让DC进行综合优化我们的设计了,这里是使用普通模式,在拓扑模式下,不支持compile命令,而是使用compile_ultra命令。电路综合优化包括三个阶段,在这三个阶段,都对设计作优化,如下图所示:
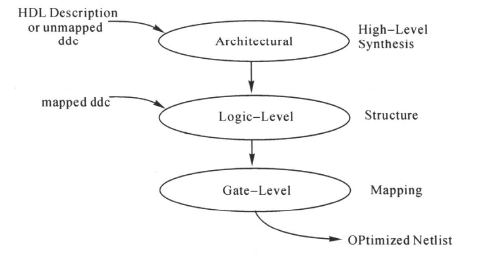
主要包括:第一阶段的结构级的优化(Architectural-Level Optimization)、第二阶段的逻辑级优化(Logic-Level Optimization)、最后阶段的门级优化(Gate-Level Optimization)。
(1)结构级的优化(Architectural-Level Optimization)
结构级优化包括的内容如下:

①设计结构的选择(Implementation Selection):
在DesignWare中选择最合适的结构或算法实现电路的功能。
②数据通路的优化(Data-path Optimization):
选择CSA等算法优化数据通路的设计。
③共享共同的子表达式(Sharing Common Subexpressions):
也就是多个表达式/等式中,有共同的表达式,进行共享,举例如下:
有等式:
SUM1<=A+B+C;
SUM2<=A+B+D;
SUM3<= A+B+E;
很容易看出,上面的等式中有共同的表达式A+B,那么代码子表达式A+B可以被共用,原等式可改为:
Temp=A+B;
SUM1<=Temp+C;
SUM2<= Temp+D;
SUM3<=Temp+E;
这种方法可以把比较器的数目减少,共享共同的子表达式。
④资源共享(Resource Sharing):
对于下面的代码:

DC中经过资源共享之后,就会得到综合出仅用一个加法器和两个多路传输器的设计,如下图所示,从而节省资源:

算术运算资源共享的默认策略是约束驱动的。我们也可以指示DC使用面积优化的策略。即将变量hlo_resource_allocation设置为area,如下所示:
set hlo_resource_allocation area
如果不希望资源共享,可以将即将变量hlo_resource_allocation设置为none,这时候,我们还是要进行算术运算的资源共享,那么我们必须在RTL代码中写出相应的代码,如下所示:

⑤重新排序运算符号(Reordering Operators):
RTL代码包含有电路的拓扑结构。HDL编译器从左到右解析表示式。括号的优先级更高。DC中DesignWare以这个次序作为排序的开始。
例如:表达式SUM<= A*B+C*D+E+F+G,在DC中的综合的结构如下图所示:
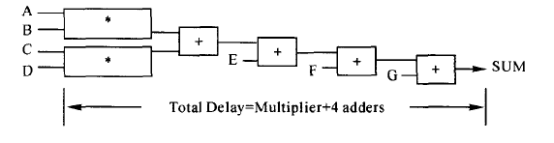
电路的总延迟等于一个乘法器的延迟加上4个加法器的延迟。为了使电路的延迟减少,我们可以改变表达式的次序或用括号强制电路用不同的拓扑结构。如:

这时得到的综合结构为:
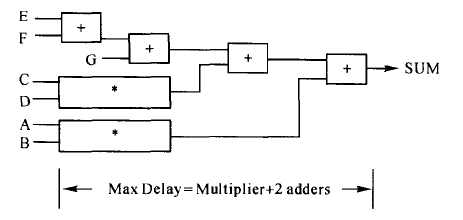
电路的总延迟等于一个乘法器的延迟加上2个加法器的延迟,比原来的电路少了2个加法器的延迟。
(2)逻辑级优化(Logic-Level Optimization)
逻辑优化的内容如下:

做完结构的优化后,电路的功能以GTECH的器件来表示。在逻辑级优化的过程中,可以作结构(Structuring)优化和展(开)平(Flattening)优化。
①结构优化:
结构(Structuring)优化用共用子表达式来减少逻辑,这种方式既可用作速度优化又可用作面积优化。结构优化是DC默认的逻辑级优化策略。结构优化在作逻辑优化时,在电路中加入中间变量和逻辑结构。DC作结构优化时,寻找设计中的共用子表达式。例如,对于下面的电路,优化前为:

做完结构优化后,电路和功能表达式为:

值得一提的是逻辑级的结构优化中共用子表达式和前面结构级的共用子表达式是不同的,逻辑级的结构优化指门级电路的共用子表达式,结构级的是算术电路的共用子表达式。逻辑级结构优化并不会改变设计的层次,用下面的命令设置结构优化:
set_structure true
②展平优化:
展平优化把组合逻辑路径减少为两级,变为乘积之和(sum-of-products,简称SOP)的电路,即先与(and)后或(or)的电路,如下图所示:
这种优化主要用作速度的优化,电路的面积可能会很大。用下面的命令设置展平优化:
set_flatten true -effort low | medium | high(low 、 medium、high其中一个就可以了)
命令选项“-effort”后的默认值为low,对大部分设计来说,默认值都能收到好的效果。如果电路不易展平,优化就停止。如果把选项“-effort”后的值设为medium, DC将花更多的CPU时间来努力展平设计。如果把选项“-effort”后的值设为high,展平的进程将继续直到完成。这时,可能要花很多时间进行展平优化。
结构(Structuring)优化和展平(Flattening)优化的比较:

(3)门级优化(Gate-Level Optimization)
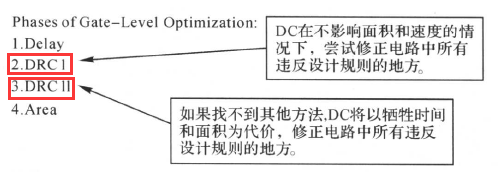
门级优化时,Design Compiler开始映射,完成实现门级电路。主要有以下内容:
映射的优化过程包括4个阶段:
阶段1:延迟优化、阶段2:设计规则修整、阶段3:以时序为代价的设计规则修整、阶段4:面积优化。
如果我们在设计上加入了面积的约束,Design Compiler在最后阶段(阶段4)将努力地去减少设计的面积。门级优化时需要映射组合功能和时序功能:
组合功能的映射的过程为:DC从目标库中选择组合单元组成设计,该设计能满足时间和面积的要求,如下图所示:



时序功能的映射的过程为:DC从目标库中选择时序单元组成设计,该设计能满足时间和面积的要求,为了提高速度和减少面积,DC会选择比较复杂的时序单元,如下所示:


设计规则修整的介绍如下:工艺库中包括厂商为每个单元指定的设计规则。设计规则有:max_capacitance,max_transition和max_fanout。映射过程中,DC会检查电路是否满足设计规则的约束,如有违反之处.DC会通过插入缓冲器( buffers)和修改单元的驱动能力(resizes cells)进行设计规则的修整。修正设计规则的步骤如下所示:
DC进行进行优化的时候,如果下面的条件之一都满足了:
①所有的约束都满足了;②用户中断;③Design Compiler到了综合结果收益递减的阶段,即再综合下去对结果也不能有多大的改善。
这时DC就会进行中断优化,停止综合。
(4)其他的优化情况(需要加上一定的综合选项开关)
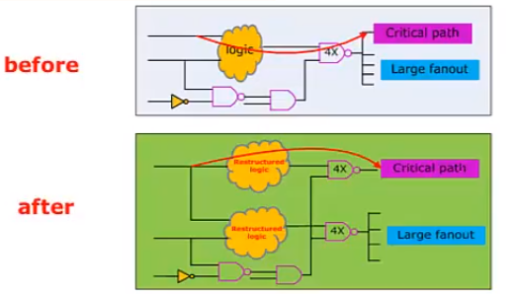
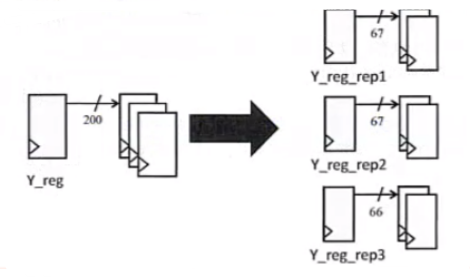
比如一个寄存器驱动多个寄存器时,可能会违反设计规则,DC会把就驱动寄存器进行复用,同时把被驱动的进行分割,如下图所示:
(使用DC的拓扑模式,加上 -timing选项才能自动地使用上面的这种寄存器复制的优化)
当你的设计中出现多次例化的情况时,也就是下面的情况:

在这种情况下,DC在编译时,会复制每个例化的模块。每个模块对应一个拷贝,并且有一个独一无二的名字。这样DC可以根据每个模块本身特有的环境做优化和映射,如下图所示((模块名字唯一化)):
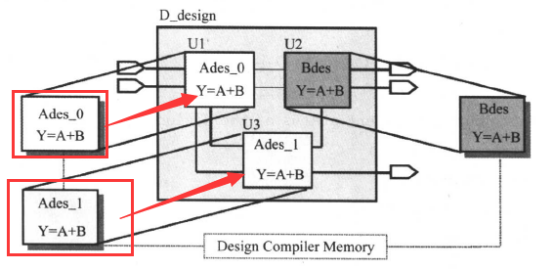
在DC里,我们可以用uniquify命令为设计中的每一个模块产生一个名字唯一的拷贝。DC在为设计做综合(compile)时,也会自动地为每一个模块产生一个唯一的有名字的拷贝。变量uniquify_naming_style可以用来控制多次例化子模块每个拷贝的命名方式。其详细的使用方法可以在DC'中用“man uniquify_naming_style”来查看。
2.时序优化及方法
DC综合之后,我们查看详细的报告,如果没有违规,设计既能满足时间和面积的要求又不违犯设计规则,那么综合完成。可以把门级网表和设计约束等交给后端(backend)工具做布局(placement )、时钟树综合(clock tree synthesis)和布线(route)等工作,产生GDSII文件。如果设计不能满足时间和面积的要求或违犯设计规则等,就要分析问题所在,判断问题的大小,然后采取适当的措施解决问题。问题往往是时序的问题,发生时序违规时可以采取相应的措施,如下图所示:
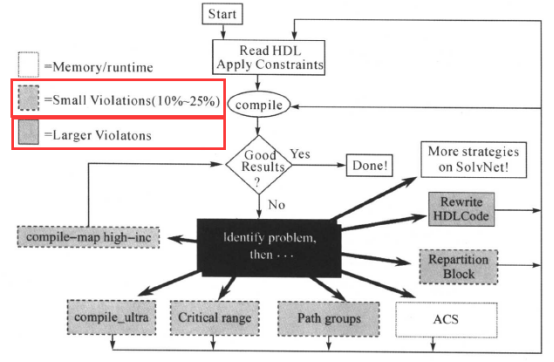
(1)当违规得比较严重时,也就是时序的违规(timing violation)在时钟周期的25%以上时,就需要重新修改RTL代码了。
(2)时序违规在25%以下,有下面的时序优化方法:
①使用compile_ultra命令(在拓扑模式下运行)
compile_ultra跟compile一样,是进行编译的命令。compile_ultra命令适用于时序要求比较严格,高性能的设计。使用该命令可以得到更好的延迟质量( delay QoR ),特别适用于高性能的算术电路优化。该命令非常容易使用,它自动设置所有所需的选项和变量。下面是这个命令的一些介绍:
compile_ultra命令包含了以时间为中心的优化算法,在编辑过程中使用的算法有:A以时间为驱动的高级优化(Timing driven high-level optimization);B为算术运算选择适当的宏单元结构;C从DesignWare库中选择最好的数据通路实现电路;D映射宽扇入(Wide-fanin)门以减少逻辑级数;E积极进取地使用逻辑复制进行负载隔离;F在关键路径自动取消层次划分(Auto-ungrouping of hierarchies)。
compile_ultra命令支持DFT流程,此外compile_ultra命令非常简单易用,它的开关选项有:
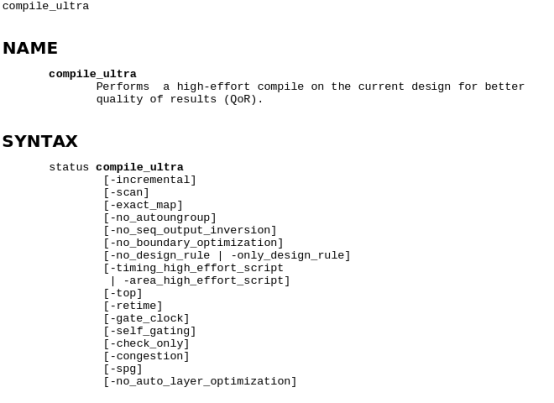
部分解释如下所示:
-scan :做可测试(DFT)编辑;
-no_autoungroup :关掉自动取消划分特性;
-no_boundary_optimization :不作边界优化;
-no_uniquify : 加速含多次例化模块的设计的运行时间
-area_high_effort_script : 面积优化
-timinq_high_effort_script : 时序优化
上面的开关部分说明如下所示:
·使用compile_ultra命令时,如使用下面变量的设置,所有的DesignWare层次自动地被取消:
set compile_ultra_ungroup_dw true (默认值为true)
也就是说,你调用的一个加法器和一个乘法器,本来他们是以IP核的形式,或者说是以模块的形式进行综合的,但是设置了上面那么变量之后,综合后那个模块的界面就没有了,你不知道哪些门电路是加法器的,哪些是乘法器的。
使用compile_ultra命令时,使用下面的变量设置,如果设计中有一些模块的规模小于或等于变量的值,模块层次被自动取消:
set compile_auto_ungroup_delay_num_cells 100(默认值=500)
也就是说,假设你有一个模块A是一个小的乘法器,并且调用了模块B,一个模块B是一个小的加法器,使用没有设置这条命令的情况综合,那么我们可以看到模块A中乘法器对应的门电路是哪些,同样也可以看到模块B的加法器是由哪些门电路构成的,模块A和模块B之间有层次、有界限;当设置上面的那条命令之后,我们就看不到模块A或者模块B之间的层次关系了,也看不到乘法器是由哪些门电路构成,或者说你看到了某一个与门,但是你并不知道它是构成乘法器的还是构成加法器的。
为了使设计的结果最优化,我们建议将compile_ultra命令和DesignWare library一起使用。
·边界优化是指在编辑(又叫综合)时,Design Compiler会对传输常数、没有连接的引脚和补码(complement)信息进行优化,如下图所示:
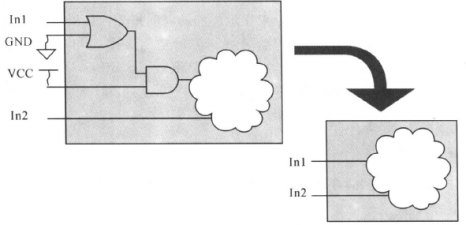
也就是说,边界优化会把边界引脚一些固定的电平、固定的逻辑进行优化。
此外,在DC Ultra(或者DC的拓扑模式下)中,我们可以用Behavioral ReTiming(简称BRT)技术,对门级网表的时序进行优化,也可以对寄存器的面积进行优化。BRT通过对门级网表进行管道传递(pipeline)(或者称之为流水线),使设计的传输量(throughput)更快。BRT有两个命令:
optimize_registers :适用于包含寄存器的门级网表(不是compile_ultra的开关选项)。
pipeline_design :适用于纯组合电路的门级网表。
对于寄存器的的优化,举例如下,对于下面的电路,既包含有组合逻辑电路又包含有寄存器:
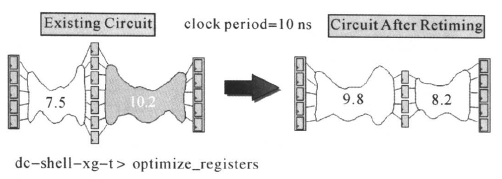
后级的寄存器与寄存器之间的时序路径延迟为10. 2 ns,而时钟周期为10 ns,因此,这条路径时序违规。但是前级的寄存器与寄存器之间的时序路径延迟为7. 5 ns,有时间的冗余。使用optimize_registers命令,可以将后级的部分组合逻辑移到前级,使所有的寄存器与寄存器之间的时序路径延迟都小于时钟周期,满足寄存器建立时间的要求。optimize_registers命令首先对时序做优化,然后对面积作优化。优化后,在模块的入/输出边界,电路的功能保持不变。该命令只对门级网表作优化。
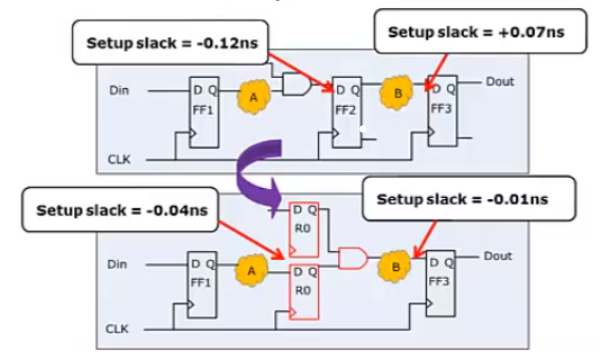
除了单独使用这个命令之外,还可以在编译的时候往往加上选项-retime(这个好像只有compile_ultra才有这个开关选项)。-retime选项的功能也就是:当有一个路径不满足,而相邻的路径满足要求时,DC会进行路径间的逻辑迁移,以同时满足两条路径的要求,这也叫adaptive retiming,如下图所示:



对于纯组合逻辑的流水线(管道)优化,举例如下,对于纯组合逻辑电路进行优化如下所示:
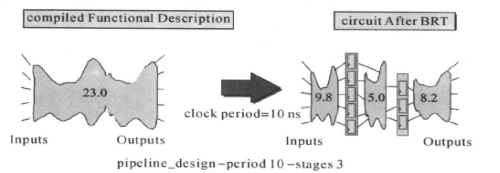
左边电路,是一个纯组合电路,它的路径延迟为23. 0 ns。对这个电路进行管道传递优化后,得到右边所示的电路。显然,电路的传输量(throughput)加快了。需要注意的是,在使用这个命令时,需要在RTL设计中把寄存器预置好,否则DC不知道这些寄存器是怎么来的。
②使用compile -scan -inc 命令
-inc 是使用增量编译。这条命令就是进行支持可测性设计的增量编译。使用增量编辑时,DC只作门级优化,这时,设计不会回到GTECH,如下图所示:


③使用自定义路径组合关键范围
在介绍这种优化方法之前,先来了解一下路径分组与延时。
·路径分组:
DC为了便于分析电路的时间,时序路径又被分组。路径按照控制它们终点的时钟进行分组。如果路径不被时钟控制,这些路径被归类于默认(Default)的路径组。我们可以用report_path_group命令来报告当前设计中的路径分组情况。例如,对于下面的电路,我们来看一下路径及分组情况:
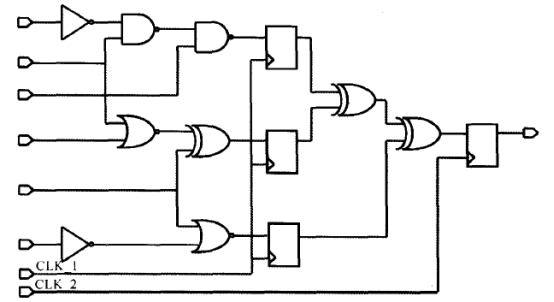
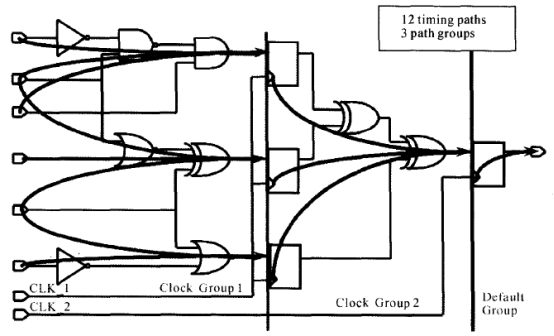
根据上图可以知道,图中共有5个终点(四个寄存器和一个输出)。时钟CLK1控制3个终点,在CLK1的控制下有8条路径。时钟CLK2控制一个终点,在CLK2的控制下有3条路径。输出端口为一终点,它不受任何时钟控制,其起点为第二级寄存器的时钟引脚,在它的控制下只有一条路径,这条路径被归类于默认的路径组。因此,本设计中共有12条路径和3个路径组。该3个路径组分别为CLKI,CLK2和默认(Default )路径组。
·路径的延时:
在计算路径的延迟时,Design Compiler把每一条路径分成时间弧((timine arcs),如下图所示:
DC就是通过时间弧来计算路径延时。因为时间弧描述单元或/和连线的时序特性。单元的时间弧由工艺库定义,包括单元的延迟和时序检查(如寄存器的setup/hold检查,clk->q的延迟等);连线的时间弧由网表定义。在上面电路中,时间弧有连线的延迟,单元的延迟和寄存器的clk -> q延迟。单元延迟常用非线性模型计算;连线延迟在版图前用线负载模型计算;RC寄生参数的分配用操作条件中的“Tree-type”属性决定;工作条件又决定制程、电压和温度对连线及单元延迟的影响。
此外,路径的延迟与起点的边沿有关,如下图所示:
假设连线延迟为0,如果起点为上升沿,则该条路径的延迟等于1. 5 ns。如果起点为下降沿,则该条路径的延迟等于2. 0 ns。由此可见,单元的时间弧是边沿敏感的。Design Compiler说明了每一条路径延迟的边沿敏感性。还有需要强调的是Design Compiler默认的行为是假设寄存器之间的最大延迟约束为:TCLK - FF21ibSetup,即数据从发送边沿到接收边沿的最大延迟时间要小于一个时钟周期,如下图所示:
Design Compiler中,常用report_timing命令来报告设计的时序是否满足目标。执行report_timing命令时,DC做4个步骤:
·把设计分解成单独的时间组;
·每条路径计算两次延迟,一次起点为上升沿,另一次起点为下降沿;
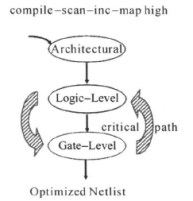
·在每个路径组里找出关键路径(critical path),即延迟最大的路径;
·显示每个时间组的时间报告。
关于怎么阅读时序报告,我们后面进行介绍。
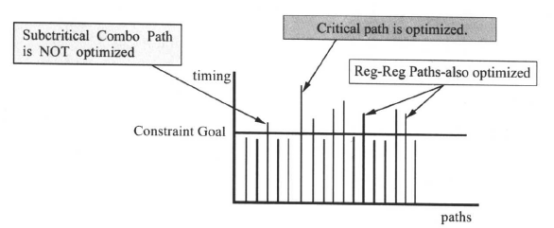
DC的默认行为是对关键路径作优化。当它不能为关键路径找到一个更好的优化解决方案时,综合过程就停止。DC不会对次关键路径(Sub-critical paths)作进一步的优化。因此,如果关键路径不能满足时序的要求,违反时间的约束,次关键路径也不会被优化,它们仅仅被映射到工艺库,如下图所示:

对于下面的电路,假设加设计约束后,所有的路径属于同样的时钟组,也就是只有一个路径组:
如果组合电路部分的优化不能满足时序要求,并且关键路径在组合电路里,根据DC的默认行为,组合电路中关键路径的优化将会阻碍了与它属于相同时钟组的寄存器和寄存器之间路径的优化。防止出现这种情况可用下面两种方法:自定义路径组和设置关键范围。
·自定义路径组(User-Defined Path Group):
综合时,工具只对一个路径组的最差(延时最长)的路径作独立的优化,但并不阻碍另外自定义路径组的路径优化。产生自定义路径组也可以帮助综合器在做时序分析时采用各自击破(divide-and-conquer)的策略,因为report_timing命令分别报告每个时序路径组的时序路径。这样可以帮助我们对设计的某个区域进行孤立,对优化作更多的控制,并分析出问题所在,如下图所示的:

产生自定义路径组的命令如下所示:
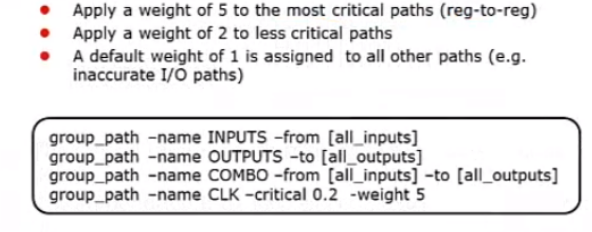
#Avoid getting stuck on one path in the reg-reg group
group_path -name INPUTS -from [all_inputs]
group_path -name OUTPUTS -to [all_outputs]
group_path -name COMBO -from [all_inputs] -to [all_outputs]
上面的命令产生三个自定义的路径组,加上原有的路径组,即寄存器到寄存器的路径组(因为受CLK控制,默认的是CLK的路径组),现在有4个路径组。组合电路的路径,属于“COMBO”组,由于该路径组的起点是输入端,在执行“group_path -name INPUTS -from [all_inputs]”命令后,命令中用了选项“-from [all_inputs]",它们原先属于“INPUTS”组。在执行“group_path -name OUTPUTS -to [all_outputs]”命令后,组合电路的路径不会被移到“OUTPUTS”组,因为开关选项‘'-from”的优先级高于选项”-to”,因此组合电路的路径还是留在“INPUTS”路径组。但是由于“group_path -name COMBO -from [all_inputs] -to [all-outputs]”命令中同时使用了开关选项“-from”和“-to" ,组合电路路径的起点和终点同时满足要求,因此它们最终归属于“COMBO”组。DC以这种方式工作来防止由于命令次序的改变而使结果不同。我们可以用report_path_group命令来得到设计中时序路径组的情况。
产生自定义的路径组后,路径优化如下图所示,此时,寄存器和寄存器之间的路径可以得到优化:
DC可以指定权重进行优化,当某些路径的时序比较差的时候,可以通过指定权重,着重优化该路径。权重最高5,其次是2,默认是1;因此最差的要设置5;如下图所示,下面的命令就是着重优化CLK这个路径组:
·关键范围(Critical Range):
DC默认只对一个路径组内的关键路径进行时序优化,但是我们可以设置DC在关键路径的延时下面某个延时值之内的路径进行优化,因此我们可以使用下面的命令设置关键范围:set_critical_range 2 [current_design]
使用上面的命令之后,DC会对在关键路径2ns的范围内的所有路径作优化,解决相关次关键路径的时序问题可能也可以帮助关键路径的优化。时序优化的示意图如下所示:
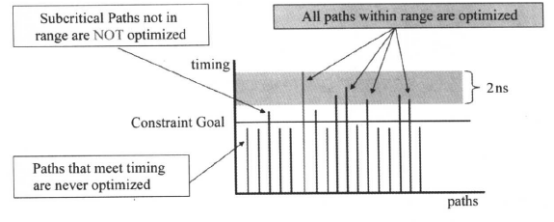
如果在执行set_critical_range命令后,优化时使关键路径时序变差,DC将不改进次关键路径的时序。我们建议关键范围的值不要超过关键路径总值的10%。
·自定义路径组+关键范围
这是将自定义路径组合关键范围结合起来,也就是在每一个路径组用指定的关键范围来设置设计的关键范围,命令如下所示:
group_path -name CLK1 -critical_range 0.3
group_path -name CLK2 -critical_range 0.1
group_path -name INPUTS -from [all_inputs] -critical_range 0
同时使用自定义时序路径组和关键范围,会使DC运行时间加长,并且需要使用计算机的很多内存。但这种方法值得一试,因为DC默认地只在每个路径组优化关键路径。如果在一条路径上关键路径不能满足时间,它不会尝试其他的方法对该时序路径组的其他路径做优化。如果能使DC对更多的路径做优化,它可能在对设计的其他部分做更好的优化。在数据通路的设计中,很多时序路径是相互关联的,对次关键路径的优化可能会改进关键路径的时序。设置关键范围后.即使DC不能减少设计中的最差负数冗余(Worst NegativeSlack,我也不知道这是什么东西),它也会减少设计中总的负数冗余(Total Negative Slack) 。
下面是自定义路径组和关键范围的主要区别:
自定义路径组: 用户自定义路径组后,如果设计的总性能有改善,DC允许以牺牲一个路径组的路径时序(时序变差)为代价,而使另一个路径组的路径时序有改善。在设计中加入一个路径组可能会使时序最差的路径时序变得更差。
关键范围: 关键范围不允许因为改进次关键路径的时序而使同一个路径组的关键路径时序变得更差。如果设计中有多个路径组,我们只对其中的一个路径组设置了关键范围,而不是对整个设计中的所有路径组都设置了关键范围,DC只会并行地对几条路径优化,运行时间不会增加很多。
④重新划分模块(Repartition Block)
模块的划分是在设计一开始就进行的,但是由于我们是注重DC这个工具的使用,因此放在这里讲解。
·层次结构与模块划分:
层次结构在IC设计中广泛使用。现代的IC设计中,几乎没有不用层次结构进行设计的。一些大的设计,其逻辑层次可能多达十几层。SoC设计中一般包括设计的再使用和知识产权IP核。SoC设计中包括了多个层次的电路。层次化的IC设计趋势如下所示:
SoC设计由一些模块组成,如下图所示:
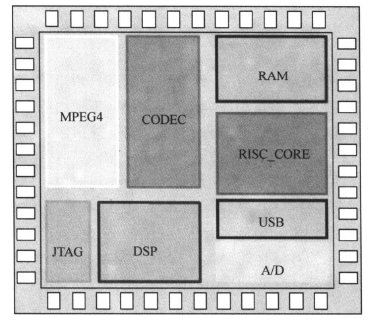
同样,图中已综合逻辑电路(例如RISC_CORE),一般也由一些子模块组成。对于设计复杂规模又大的电路,我们需要对它进行划分(Partitioning),然后对划分后比较简单规模又小的电路作处理(如综合)。这时,由于电路小,处理和分析比较方便简单。容易较快地达到要求。再把已处理好的小电路集成为原来的大电路,如下图所示:
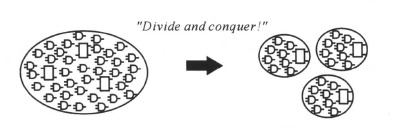
理想情况下,所有的划分应该在写HDL代码前已经计划好。
·初始的划分由HDL定义好.
·初始的划分可以用Desige Compiler进行修改.
做划分的原因很多,下面是其中的几个原因:
·不同的功能块(如Memory,uP,ADC,Codec、控制器等等);
·设计大小和复杂度(模块处理时间适中,设计大小一般设为一个晚上的运行时间,白天进行人工处理和调试,晚上机器运行,第二天上午检查运行结果);
·方便设计的团队管理项目(每个设计工程师负责一个或几个模块);
·设计再使用(设计中使用IP);
·满足物理约束(如用FPGA先做工程样品—Engineering Sample;大的设计可能需要放入多个FPGA芯片才能实现)。
·等等。
划分模块关系到时序,时序不好的情况下,可以进行重新划分模块,因此就要求我们在划分模块的时候,对设计进行合适的划分。
可用例化(instantiation)定义设计的层次结构和模块(hierarchical structure and blocks)。 VHDL的entity和Verilog的module的陈述(statements)定义了新的层次模块,即例化一个entity或module产生一级新的层次结构。如果设计中,我们用符号(+,一,*,/,…)来标示算术运算电路,可能会产生一级新的层次结构。VHDL语言中的Process和Verilog语言中的Always陈述并不能产生一级新的层次。设计时,为了得到最优的电路,我们需要对整个电路作层次结构的设计,对整个设计进行划分,使每个模块以及整个电路的综合结果能满足我们的目标。
例如下面的设计中:

有3个模块:A,B和C。它们各自有输入和输出端口。由于DC在对整个电路做综合时,必须保留每个模块的端口。因此,逻辑综合不能穿越模块边界,相邻模块的组合逻辑也不能合并。从寄存器A到寄存器C的路径的延时较长,这部分的电路面积较大。 如果我们对设计的划分作出修改,相关的组合电路组合到一个模块,原来模块A,B和C中的组合电路没有了层次的分隔,综合工具中对组合电路优化的技术现在能得到充分的使用。这时,电路的面积比原来要小,从寄存器A到寄存器C的路径的延时也短了。修改如下图所示:

如果我们对设计的划分作另一种修改,如下所示,我们将得到最好的划分:
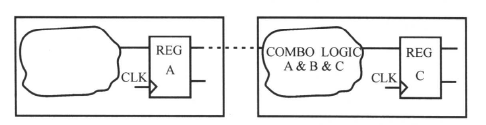
这里的修改将相关的组合电路组合到一个模块,原来模块A,B和C中的组合电路没有了层次的分隔,综合工具中对组合电路优化的技术能得到充分的使用。并且,由于组合电路和寄存器的数据输入端相连,综合工具在对时序电路进行优化时,可以选择一个更复杂的触发器((JK,T,Muxed和Clock-enabled等),把一部分组合电路吸收集成到触发器里。从而使电路的面积更小,从寄存器A到寄存器C的路径的延时更短。
对于一般的设计,好的模块划分如下图所示:
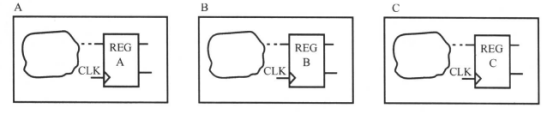
在这样的划分下,模块的输出边界是寄存器的输出端。由于组合电路之间没有边界,其输出连接到寄存器的数据输入端,我们可以充分利用综合工具对组合电路和时序电路的优化技术,得到最优的结果,同时也简化了设计的约束。图中每个模块除时钟端口外的所有输入端口延时是相同的,等于寄存器的时钟引脚CLK到输出引脚Q的延时。这使得时序约束更为方便,这一点在前面的时序路径约束中有说过。
上面是推荐的模块划分模式,下面就来说一下哪些是要避免的模块划分方式。
作模块划分时,应尽量避免使用胶合逻辑(Glue Logic),胶合逻辑如下图所示:
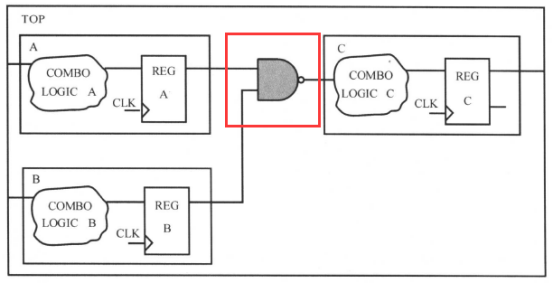
胶合逻辑是连接到模块的组合逻辑。图中,顶层的与非门(HAND gate)仅仅是个例化的单元,由于胶合逻辑不能被其他模块吸收,优化受到了限制。如果采用由底向上(bottom up)的策略,我们需要在顶层做额外的编译(compile)。避免使用胶合逻辑(Glue Logic)的划分如下所示:
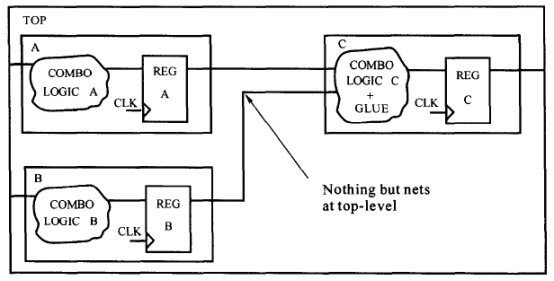
胶合逻辑可以和其他逻辑一起优化,顶层设计也只是结构化的网表。不需要再做编译。
·模块划分的修改
第一次的模块划分可能存在时序违规,可能需要重新划分模块,这里就来介绍一下模块划分的修改问题。我们知道,设计越大,计算机对设计作综合时所需要的资源越多,运行时间就越长。Design Compiler软件本身对设计的规模大小并没有限制。我们在对设计做编译时,需要考虑划分模块规模的大小应与现有的计算机中央处理器(CPU)和内存资源相匹配。尽量避免下面划分不当情况:
模块太小:由于人工划分的模块边界,使得优化受到限制,综合的结果可能不是最优的。
模块太大:做编辑所需的运行时间可能会太长,由于要求设计的周期短,我们不能等太久。
一般来说,根据现有的计算机资源和综合软件的运算速度,按我们所期望的周转时间(turnaround time),把模块划分的规模定为大约400 ~800K门。对设计作综合时,比较合理的运行时间为一个晚上。白天我们对电路进行设计和修改,写出编译的脚本。下班前,用脚本把设计输人到DC,对设计作综合优化,第二天早上回来检查结果。
作划分时,要把核心逻辑(Core Logic) 、 I/0 Pads、时钟产生电路、异步电路和JTAG(Joint Test Action Group)电路分开,把它们放到不同的模块里。顶层设计至少划分为3层的层次结构:顶层(Top-level)、中间层(Mid-level)、核心功能(Functional Core),如下图所示:
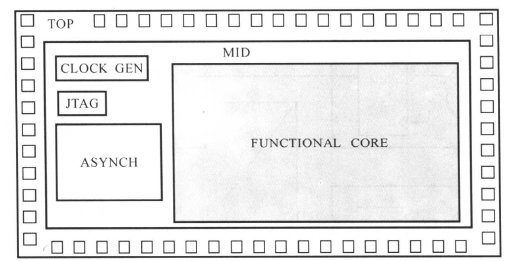
使用这种划分方式是因为:I/O pad单元与工艺相关、分频时钟产生电路是不可测试(Untestable)的、JTAG电路与工艺相关、异步电路的设计、约束和综合与同步电路不同,所以也放在与核心功能不同的模块里。
这里主要介绍同步电路的设计与综合。 为了使电路的综合结果最优化,综合的运行时间适中,我们需要对设计作合适的划分。如果现有的划分不能满足要求,我们要对划分进行修改。我们可以修改RTL原代码对划分作修改,也可以用DC的命令对划分作修改。下面介绍在DC里用命令修改划分。
DC以两种方法修改划分:自动修改划分和手动修改划分。
自动修改划分:
综合过程中DC需透明地修改划分。在DC中如使用命令:
compile -auto_ungroup area | delay (面积和延时之中选一个)
DC在综合时将自动取消(去掉)小的模块分区。取消模块分区由变量(前面也有提及到这些命令):
compile_auto_ungroup_delay_num_cells
compile_auto_ungroup_area_num_cells
来控制。两个变量的预设默认值分别为500和30。我们也可以用set命令把它们设置为我们希望的任何数值。我们可用report_auto_ungroup命令来报告编辑时取消了那些分区。如在DC中使用命令:
compile -ungroup_all
DC在综合时将自动取消所有的模块分区或层次结构。此时,设计将只有顶层一层的电路。该命令不能取消附加了dont_touch属性的模块分区。
手工修改划分:
手动修改划分是指用户用命令指示所有的修改。使用“group”和“ungroup”命令修改设计里的划分,如下图所示:
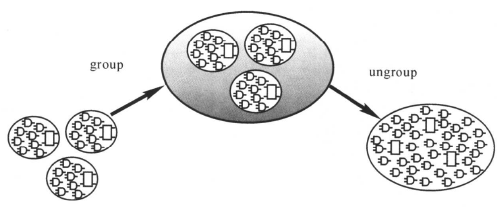
group命令产生新的层次模块,效果如下图所示:
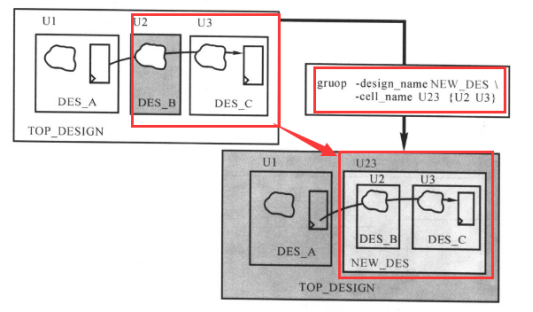
ungroup命令取消一个或所有的模块分区,效果如下图所示:
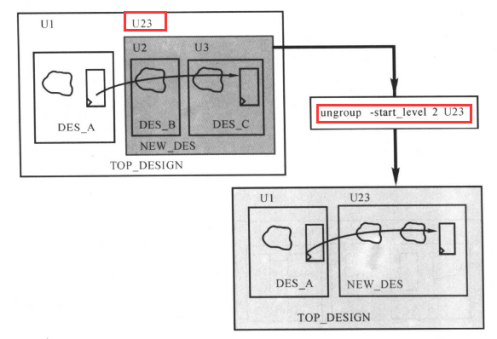
如要在当前设计中取消所有的层次结构,可以使用下面的命令:
ungroup -all -flatten
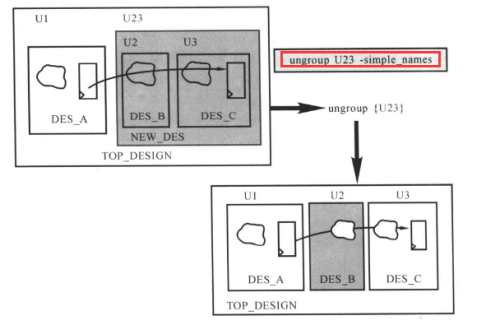
ungroup命令用选项“-simple_names”将得到原来的非层次的单元名U2 and U3
ungroup U23 -simple_names
得到的效果如下图所示:
最后,为了防止再次划分模块,这里总结一下模块划分的策略:
·不要通过层次边界分离组合电路。
·把寄存器的输出作为划分的边界。
·模块的规模大小适中,运行时间合理。
·把核心逻辑(Core Logic) ,Pads、时钟产生电路、异步电路和JTAG电路分开到不同的模块。
这样划分好处是:结果更好——设计小又快、简化综合过程——简化约束和脚本、编译速度更快一一更快周转时间(turnaround)。
下面是实战环节
3、实战
在本次实战里面,我们主要根据给出的原理图和综合规范,实践DC的综合优化技术,在拓扑模式下进行,因此还有可能涉及一些物理设计的内容,我们一步一步来进行吧。
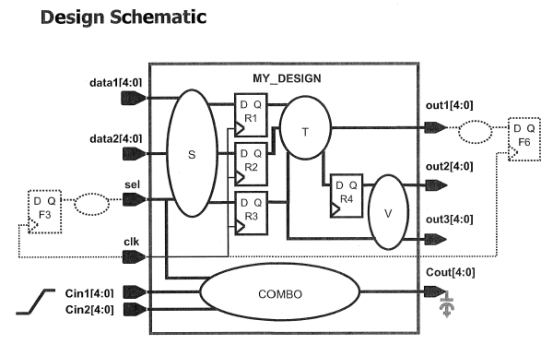
设计原理图:

(顶层模块示意图:)
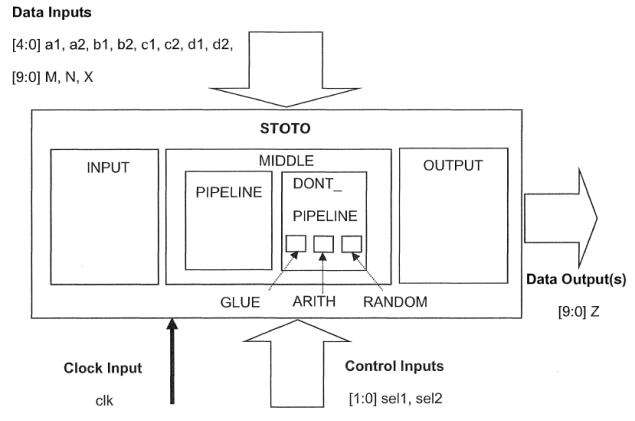
(子模块示意图一:)
(子模块示意图二:)

(子模块示意图三:)
综合规范:
(可用资源说明:)

(设计和约束文件说明:)

(布局规划说明:)

(设计规范:)

首先我们来简单分析一下这个综合规范:
可用资源规范:也就是通过运行那个脚本来查看你的电脑有多少可用用来综合的核心,这里我们跳过,不用理他。
设计和约束文件说明:告诉我们设计的RTL文件和名字,以及告诉我们约束的位置和名字,RTL文件和名字以及时序环境等约束都我们不需要改。
布局规划说明:由于我们使用的是拓扑模式下的综合,这个布局规划提供给了我们物理的约束信息。
设计规范说明:其实这个是综合的规范说明,告诉你需要在综合过程中,要对哪些模块进行怎么样的处理,从而达到某种要求,这里面的10条规范我们后面在时间过程中都会介绍。
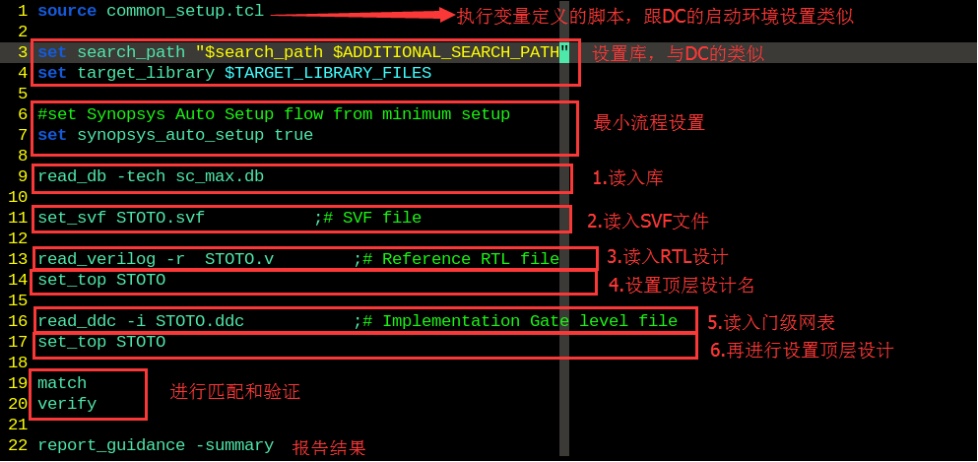
·设置.synopsys_dc.setup启动文件,配置DC的启动环境
(跟前面一样,不进行具体描述)
·进行编写设计约束文件,由于这里一方面没有给出时序和环境属性等方面设计规范,一方面给出了相关的设计约束文件,因此我们不需要进行撰写了,我来看一下吧:
时序和环境属性的约束:
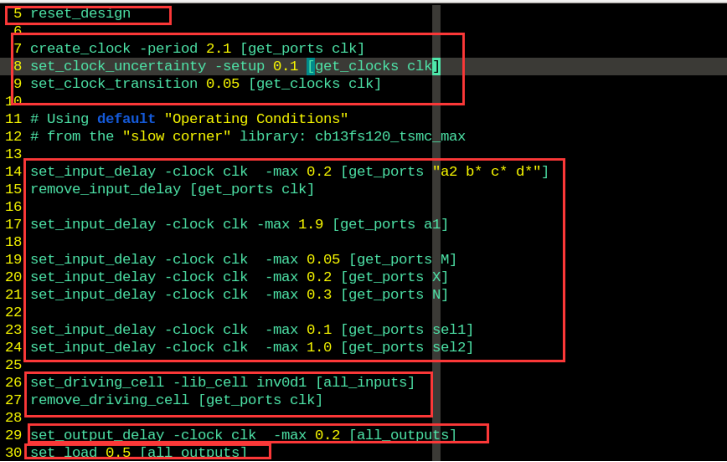
从上到下依次是:清除以前的约束、时钟的约束、输入端口延时的约束、输入端口环境属性的约束、输出端口延时约束、输出端口环境属性的约束。
布局规划中,包含的物理信息,对于了相应地物理约束,如下所示:

约束都给我们准备好了,我们就可以启动DC了
·启动DC,进行读入设计前的检查
(这里跟之前的章节一样,不再陈述)
·为formality创建文件,以便retiming转化可以捕捉到相应地文件,总之就是形式验证要用到,命令如下:
set_svf STOTO.svf
·读入设计和检查设计
(很前面的章节已经,这里不再陈述)
·执行时序约束,查看约束是否满足,同时执行非默认的物理约束:
source STOTO.con
check_timing
source STOTO.pcon
report_clock
·根据设计规范,应用不同的优化命令:
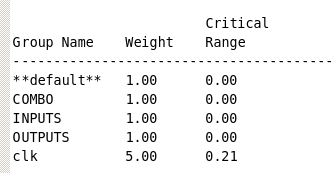
-->根据1和2,IO约束是保守值,能够更改,还有就是最终的设计要满足寄存器到寄存器之间的路径,因此,我们可以进行路径分组,并且更关注时钟那一组,也就是寄存器到寄存器那一组,优化的命令如下所示:
group_path -name clk -critical 0.21 -weight 5
group_path -name INPUTS -from [all_inputs]
group_path -name OUTPUTS -to [all_output]
group_path -name COMBO -from [all_inputs] -to [all_output]
然后我们可以查看时候进行了设置:
report_path_group,得到结果如下:
-->根据3,INPUT模块的结构需要保护;根据4,PIPELINE模块需要进行register_timing,也就是纯的流水线,因此也不能被打散,因此需要设置:
set_ungroup [get_designs "PIPELINE INPUT"] false
设置之后我们需要查看是否设置正确(设置正确会返回false )
get_attribute [get_designs "PIPELINE INPUT"] ungroup
如下图所示:

ungroup是取消层次的依次,设置为true就是要进行取消层次结构;因此我们要设置为false
-->根据6,I_DONT_PIPELINE模块的寄存器不能被流水线移动,根据前面的讲解,我们可以这样约束:
set_dont_retime [get_cells I_MIDDLE/I_DONT_PIPELINE] true
然后检查是不是约束成功,或者约束对了:
get_attribute [get_cells I_MIDDLE/I_DONT_PIPELINE] dont_retime
如下图所示,返回应为true:

-->根据要求4,需要进行pipelined,于是我们可以启用register_timing,约束如下所示:
set_optimize_registers true -design PIPELINE
-->根据要求5,虽然PIPELINE进行了pipelined,也就是进行了寄存器retiming,但是输出寄存器不能动,也就是保持原来的寄存器,因此需要约束:
set_dont_retime [get_cells I_MIDDLE/I_PIPELINE/z_reg*] true
然后检查一下是否正确:

-->保存在综合之前保存一下我们的设计:
write -f ddc -hier -out unmapped/STOTO.ddc
·进行综合:
根据要求8:设计是时序关键的,因此我们要在综合的时候加上-timing选项;根据要求10:要执行扫描插入,因此要加上-scan选项,看预加上扫描链综合后是否有违规;根据要求7、9以及前面的要求,我们可以加上-retiming选项优化进行寄存器、组合逻辑等的优化;综合使用的命令如下所示:
compile_ultra -scan -timing -retime
·综合后检查与处理:
-->综合完成之后,我们可以查查看我们用了哪些特性(这一步可以忽略):

(这些特性都是大把大把地烧钱啊)
-->查看哪些模块是否被打散,即验证与约束的是否一致:
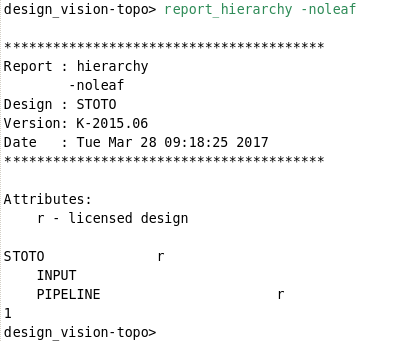
可以知道:MIDDLE, OUTPUT, DONT_PIPELINE, GLUE, ARITH and RANDOM这些模块都被打散了; 没有被打散的,也就是保存了模块结构的只有下面的这三个设计:STOTO, PIPELINE, INPUT
我们从GUI中也可以看到:
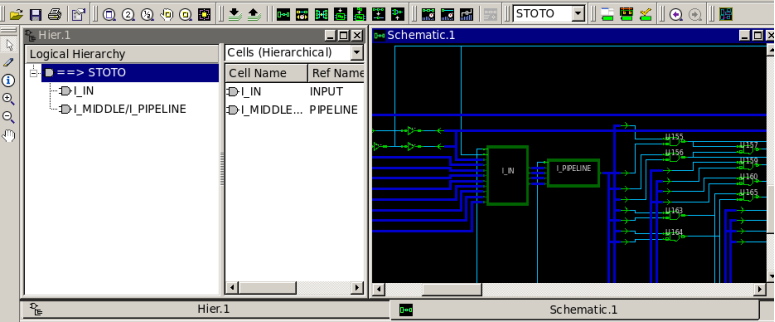
只有顶层设计STOTO和子模块PIPELINE, INPUT的边框被保存下来了,其他的都被打散了,也就是找不到模块的边界了。
-->查看是否有约束违规:
这里我们通过重定义的形式,把生成的时序报告保存到文件中:
redirect -tee -file rc_compile_ultra.rpt {report_constraint -all}
(本实验中,有时序违规)
-->查看时序报告:
redirect -tee -file rt_compile_ultra.rpt {report_timing}
下面我们就来看看这个这个时序报告的一部分吧:


从上面的报告我们可以知道,虽然一些模块被打散了,但是模块的例化明还在,我们可以通过例化名来找到原件所在的模块,方便我们查看延时不合理时提供定位;这也就是模块例化名字唯一化的一个好处。
-->保存设计:
write -f ddc -hier -out mapped/STOTO.ddc
综合完成了,此外我们为formality进行停止记录数据(总之就是形式验证要做得事):
set_svf -off
·查看寄存器是否被移动等操作,也就是查看优化技术的结果细节(有兴趣的可以仔细看下,深入了解)
前面我们进行了各种retiming、pipeline的优化,有一些寄存器被移动了,有些组合逻辑被分割了,我们现在就来看看那些被移动,一方面是纯粹的查看进行了解一些优化技术,另一方面是看看是否存在约束与预期不符合的情况。
-->查看在PIPELINE设计中被register retiming技术移动过的寄存器 :
get_cells -hier *r_REG*_S
通过返回值(即返回寄存器的名字)的路径,我们可以知道PIPELINE中的流水线寄存器被移动过了:

(retiming中被移动过的流水线寄存器的名字以 clkname_r_REG*_S*结束,*是通配符),再结合我们我们的原理图,我们可以知道,是z1_reg被移动了(一位后缀名是z1跟s1):

-->我们还可以查看例化的名字原来的模块名字,如下所示:
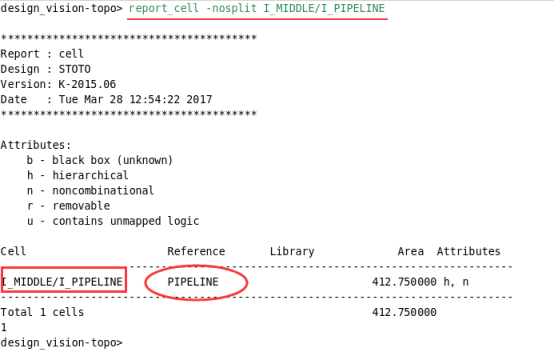
查看原来的I_IN模块:
report_cell -nosplit I_IN:

-->在第1点中我们说只是通过名字中的1来说移动的是z1_reg,这显然是不够充分,可以通过下面来验证z_reg是否被移动过:
get_cells -hier *z_reg*
有返回值,说明这个寄存器存在,没有被移动过(移动过之后就被换了例化名字):

然后我们来查看一下z1_reg,可以看到找不到对象,说明被移动了:

-->查看其它的被retiming移动都的触发器(retiming中,被移动过的却不是流水线中的寄存器的被命名为R_* ):

上面是INPUT模块中被retiming移动的寄存器,我们可以查看该模块是否有不被移动的寄存器:
get_cells I_IN/*_reg*
有返回值,说明是存在有不被移动的寄存器的。
-->通过下面的命令:
report_timing -from I_MIDDLE/I_PIPELINE/z_reg*/*
可以知道PIPELINE模块是寄存输出的(因为有返回报告值)
优化的实战部分都这里就结束了,最后,DC的优化命令有很多,不懂的可以通过man命令查看。最后感叹一下,总共码了一万两千多子,加上一堆图,这应该是本系列最长的一篇博文吧。
------------------------------
本文如果有错,欢迎留言更正;此外,转载请标明出处 http://www.cnblogs.com/IClearner/ ,作者:IC_learner
这里来讲一下formality的使用,貌似跟tcl和DC没有很强的联系;然而说没有联系,也是不正确的。在综合完成之后,可以进行形式验证。此外这里不是专门讲解formality的使用的,因此只会简单地实践一下它的用法。
formality是Synopsys公司的形式验证工具,上一节我们得到了综合后的设计,这里我们就要验证综合后的设计和我们的RTL代码是否一致。
1、准备好RTL文件、综合优化后的文件以及带有优化映射信息的SVF文件:

2、书写相应地流程文件:
3、启动formality:
fm_shell
对上面脚本不清楚的或者不懂的,可以使用man命令查看它的用法:
-->

-->

-->

-->

4、执行我们写的脚本

得到结果如下,说明验证通过了:
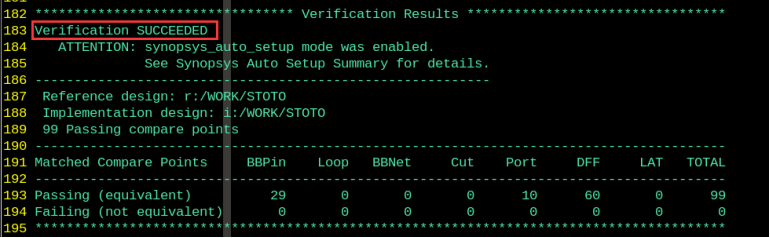
------------------
本文如果有错,欢迎留言更正;此外,转载请标明出处 http://www.cnblogs.com/IClearner/ ,作者:IC_learner
之前讲了基本的时序路径约束,现在我们来看一下其他的约束,然后通过实战来讲解一些其他的约束。实战中也没有前面的“理论”中的约束类型,但是可以通过实战来了解其他的约束。本文的具体内容是:
·多时钟同步约束
·门控时钟的约束
(实战:)
·正负边沿触发器的约束
·输入输出延时的非默认约束
·输入输出有多个路径驱动(类似多时钟同步)
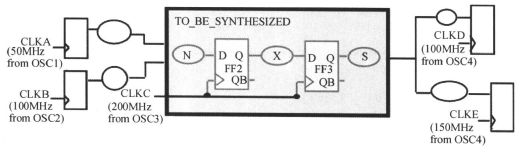
1、多时钟同步的时序约束
前面的讲了基本的时序路径约束,也就是那些约束是基于类似下面电路类型的:

模块前后的时钟是同一个,因此输入输出逻辑的路径延时约束也变得简单。下面我们来对多时钟同步设计的时序路径进行约束,多时钟电路的模型如下所示:
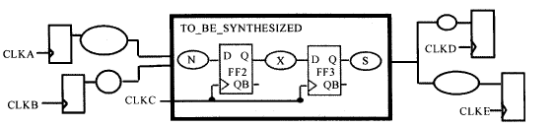
我们要综合的模块的时钟是CLKC,但是前后模块的时钟不一定是CLKC,但是前后模块的时钟跟CLKC是来源于同一个时钟的,比如说经过锁相环分频或者倍频,这里拿分频来举例,比如说CLKA、 CLKB、CLKC、CLKD、CLKE都是由同一个时钟CLK经过分频得来,如下图所示:


(虽然上面说是同步电路,但是在传统上看,上面的电路不算是同步时钟,因为他们的相位没有固定的关系;但是在这里,我们“假装”它们是同步时钟,因为理论上,是由同一个时钟分频得来的,在理想情况下,我们是可以知道它们的相位关系的)
在我们要综合的电路中,只有一个时钟端口CLKC,即只有CLKC时钟驱动要综合电路中的寄存器。其他的时钟CLKA,CLKB,CLKD和CLKE在我们要综合的电路中并没有对应的时钟端口。因此,它们并不驱动要综合电路中的任何寄存器。它们主要用于为输入/输出端口延时作约束,可能会出现一个端口有多个约束的情况。
下面我们根据上面的例子作多时钟的同步设计约束,也就是为下面的电路类型做约束:

CLKC在要综合的设计中有对应的输入端口,其定义与单时钟时一样,即:
create_clock -period 20 [get_ports CLKC]
由于CLKA,CLKD和CLKE在要综合的设计中没有对应的输入端口,因此需要使用虚拟(virtual)时钟。虚拟时钟在设计里并不驱动触发任何的寄存器,它主要用于说明相对于时钟的I/O端口延迟,DC将根据这些约束,决定设计中最严格的约束。建立虚拟时钟的格式如下:

上面定义了名字为VCLK的虚拟时钟,周期为20ns。因为虚拟时钟不驱动设计中的任何寄存器,设计中没有其对应的输入端口。所以定义中没有源端口或引脚。由于虚拟时钟没有对应的时钟端口,我们必须给它一个名字。与一般时钟一样,虚拟时钟是DC的内存里已定义的时钟物体(设计对象),它(们)不驱动(触发)当前设计中的任何寄存器。用作为输入/输出端口设置延迟。
例如,对于下面输入端口电路:
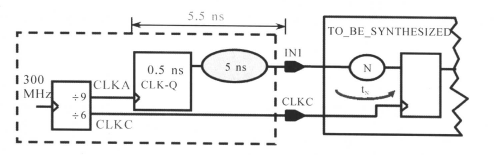
对应的约束为:
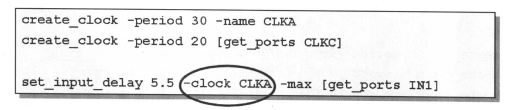
由于是直接知道了外部的约束,因此可以直接约束。注意最后一条那里,这里的输入路径的对比时钟是CLKA,而不是我们要综合的模块时钟CLKC了,此外这里的路径约束是对于输入端口IN1而言,因此要具体给出输入端口的名字,而不能用[get_ports $ALL_IN_EXCEPT_CLK]这样的了,而是要具体到某些端口了。
其输入端口的时序关系如下图所示:
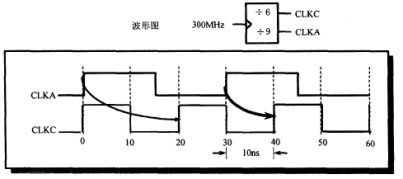
如波形图所示,要综合电路的输入部分逻辑N的延时必须满足:
20 - 5.5 - Tsetup和10 -5.5 - Tsetup两个等式中最严格的情况,也就是满足:10 -5.5 - Tsetup
(输入部分逻辑N的延时Tn满足:20ns = 5.5ns + Tn + Tsu +Tuncertainty和10ns =5.5ns + Tn + Tsu+Tuncertainty中最严格的,Tuncertainty在这里为0)由于是输入端口,数据是从CLKA时钟域传到CLKC时钟域,因此是从CLKA出发,也就是说数据从CLKA上升沿开始(时刻0),然后CLKC的下一个上升沿到来的时刻(时刻20)捕获数据,因此留给输入逻辑的延时是20 - 5.5 - Tsetup;CLKA下一个上升沿(时刻30ns处)又传输数据过来,而这时相对于CLKA的下一个CLKC上升沿在40ns处捕获数据,因此留给输入逻辑的延时是10 -5.5 - Tsetup;这两个延时必须同时满足,故满足10 -5.5 - Tsetup。
例如对于下面的输出端口电路:
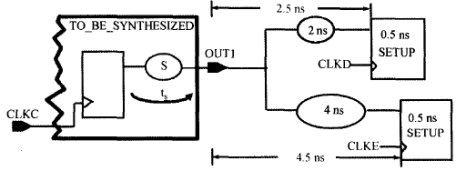
创建的虚拟时钟和对应的约束为:

第二条set_output_delay命令里,使用了-add_delay选项,意思时输出端口OUT1有多个约束,如果不加选项-add_delay,第二个set_output_delay命令将覆盖(取代)第一条set_output_delay命令,这时,输出端口OUT1只有一个约束,就达不到我们的预期要的约束了。
时钟CLKD的频率为75MHz(300MHz/4),为了计算时钟周期,我们需要用实数来得到时钟的周期。要注意的是[expr 1/75*1000]与[expr 1.0/75*1000]得到的结果是不一样的,前者是0,后者不为0的实数。
上面输出端口电路的约束对应的时序关系如下图所示:
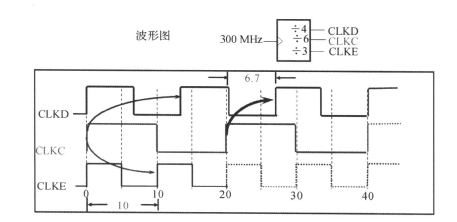
要综合电路的输出部分S必须满足:Ts<10-4.5和Ts<6.7-2.5中最严格的要求,也就是Ts<6.7-2.5。
(Ts满足:10ns = Ts + Tuncertainty + 4.5ns和6.7ns=Ts+Tuncertainty+2.5ns中最严格的)
与前面的类似,只不过这里是数据输出端口,CLKC的上升沿是数据发送沿,CLKD和CLKE是数据接收端,因此都是从CLKC出发。比如CLKC分别从0时刻和20时刻出发,到CLKD或者CLKE的上升沿结束,跟前面同理,由此也可以得出最严格的延时约束是Ts<6.7-2.5。
由此可见,综合时,DC计算出所有时钟的公共基本周期(common base period),计算出每个可能的数据发送/数据接收时间,按最严格的情况对电路进行综合。这样可以保证得到的结果能满足所有的要求(约束),达到设计目标。
2、门控时钟的时序约束
门控时钟(gated clock)是进行低功耗电路设计的一种有效和常用方法。下图是门控时钟的一个例子:
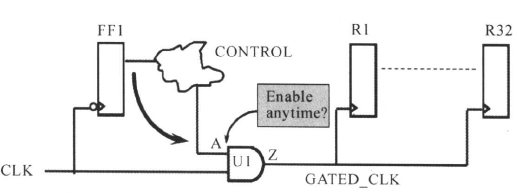
门控时钟有理想的,也有有问题的情况,如下图所示:

从上面的电路图和波形图中,很容可以看出时钟的控制边沿为上升沿,门控使能信号在逻辑高电平起作用(被激活)。如果门控使能信号Cgate在时钟上升沿之前没有变化(从有效变成无效或者从无效变成有效),而是上升沿过后,门控信号才发生变化,这时门控电路的输出会产生毛刺(glitches)。
关于门控制时钟的使能信号电路模型和时序关系图如下所示:

对应的门控时钟约束为:

需要说明的是,DC能自动辨认门控时钟电路。综合时,DC将根据上述的约束在门控时钟电路中增加/删除逻辑以满足门控使能信号的建立和保持时间要求。
关于门控时钟,下面进行简单叙述。有两种门控时钟单元,一种是无锁存器(latch free)门控时钟单元,另一种是基于锁存器(latch based)门控时钟单元。前面的例子中的门控时钟单元是无锁存器的门控单元。基于锁存器门控时钟单元的结构如下图所示:
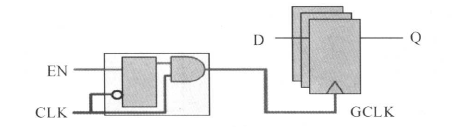
这种电路结构的行为表现好像一个主从(master-slave)寄存器,它在时钟的上升沿捕获门控使能信号。这种结构的门控时钟单元的输出如下所示:
我们可以看到基于锁存器门控时钟单元不产生毛刺,因此我们建议大家使用这种门控时钟电路。但是无论使用哪种门控时钟,都会使其驱动的寄存器时钟引脚信号不能由输入端直接控制,从而降低了电路的测试覆盖率,这是要注意的(关于什么是测试覆盖率,请参考有关书籍)。
3、实战
本次的实战是进行其他选项的时序约束,下面直接来实战吧,不废话了:
设计原理图:
设计规范:

①准备还相关的设计源文件、编写.synopsys_dc.setu相关的配置文件
这一步跟前面章节的步骤类似,这里不再详述。
②在前面相关章节的约束基础上,根据设计规则进行书写相关的约束条件:
-->首先这个时钟名字为my_clk,占空比为40%(高电平占40%),没有偏移(这里的偏移是offset,而不是skew),因此之前创建时钟的约束可以改为:
create_clock -period 3.0 -name my_clk -waveform {0 1.2} [get_ports clk]
其他的时钟约束需要把clk改成my_clk,然后在进行其他的输入输出等延时约束时,需要注意其对应的时钟改为my_clk。
-->附加的输入延时约束:
这里的输入延时约束是在之前的输入延时约束的基础上附加的,我们先来看看这个约束的要求:
1.sel端口的数据也由附加的寄存器F4提供,在F4的时钟下降沿触发之后,数据到达sel端口的时间不超过420ps。
2.时钟信号从时钟源到F4的时钟端口有600ps的延时(包括外部的source 延时 和 内部的network延时)。
根据上面两点,我们可以这么约束:
set_input_delay -max 1.02 -clock my_clk -add_delay -clock_fall -network_latency_included -source_latency_included [get_ports sel]
怎么理解这句约束呢?我们先来看一下set_input_delay -max 这个命令的约束选项:
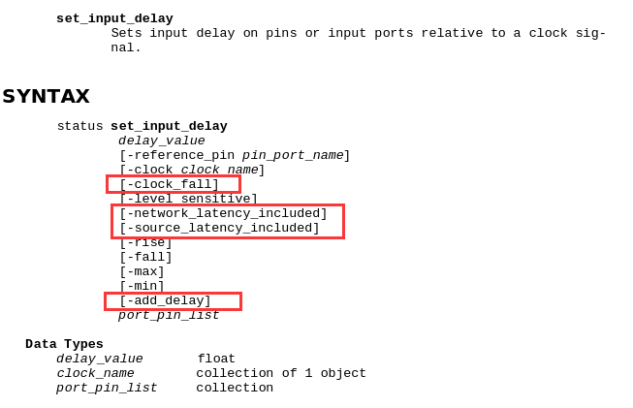




首先是420ps的延时,这是直接给出了外部的延时;然后呢,又有时钟信号的延时600ps,因此我们这个附加的输入延时总量为420ps+600ps = 1.02ns。这里由于是附加的约束条件,因此需要加上-add_delay的选项;由于是下降沿触发,因此需要-clock_fall的选项;最后需要指明这延时不是添加在输入延时上面的,而是包含在本身的时钟延时上面的。
-->附加的输出延时约束:
首先1.那里的意思是说输出端口out1的数据被F5寄存器捕获;在F5的下降沿到来之前,数据必须不晚于260ps到达out1端口,如下图所示:
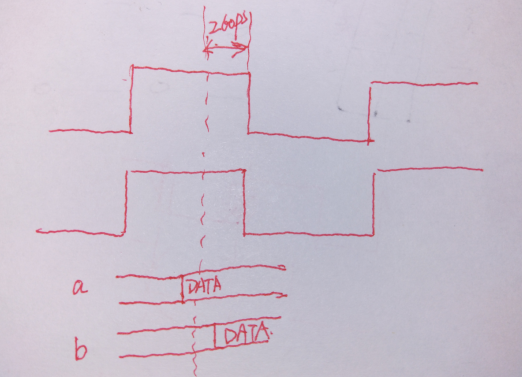
情况a是符合要求的,而情况b是不符合要求的。
然后是2.那里,意思是F5的network延时有500ps;当没有这个延时要求的时候,我们在下降沿附加的外部延时约束就是260ps,但是由于这500ps的延时,导致了下降沿推后,如下图所示:
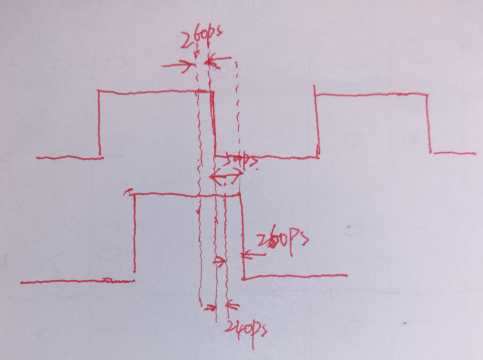
这个时候,外部延时的约束就是260-500=240ps了,也就是说,模块内部的组合逻辑增加了240ps的时间延时余量,具体的约束如下所示:
set_output_delay -max -0.24 -clock my_clk -add_delay -clock_fall -network_latency_included [get_ports out1]
-->最后是输入端负载的约束,每个输入端口都扇出到另外两个子模块(除了clk),每个子模块在内部驱动相当于3个bufbd1(输入引脚I)缓冲器,然后要求给输入端约束这个外部的电容负载;我们得到的约束如下所示:
set all_in_ex_clk [remove_from_collection [all_inputs] [get_ports clk]]
set_load [expr 6 * {[load_of cb13fs120_tsmc_max/bufbd1/I]}] $all_in_ex_clk
③启动DC,进行读入设计前的检查
跟前面章节步骤一样,不再详述。
④读入设计与读入后的检查
跟前面章节步骤一样,不再详述。
⑤进行约束设计与检查是否正确约束上
跟前面章节步骤一样,不再详述。
⑥进行综合和综合后检查
跟前面章节步骤一样,不再详述。
⑦写出相关的报告或者文件
跟前面章节步骤一样,不再详述。
-------------------
本文如果有错,欢迎留言更正;此外,转载请标明出处 http://www.cnblogs.com/IClearner/ ,作者:IC_learner
前面介绍的设计都不算很复杂,都是使用时钟的默认行为作为电路的约束,都存在有路径给你约束,即信号的变化要在一个时钟周期内完成,并达到稳定值,以满足寄存器的建立和保持的要求。此外进行可测性设计(design for test)时,为了提高测试的覆盖率,我们经常使用多路(multiplex,简称mux)传输电路的控制时钟,使电路的时钟信号可以由输入端直接控制。这些电路约束属于复杂的约束,除了理论上的讲解之外,还会进行实战,实战内容主要为围绕前面的伪路径和多周期路径进行的,主要内容如下:
·异步设计路径和逻辑上不存在的路径的时序约束(时序例外)
·多时钟周期的时序约束
·分频电路和多路时钟传输的时钟约束
·实战
1、异步设计路径和逻辑上不存在的路径的时序约束(时序例外)
(1)异步设计的路径约束
前面说的都是同步时序电路,下面就用介绍一下异步时序电路的约束吧。异步时序电路的时钟来自不同的时钟,模块之间的时钟是不同频或者同频不同相的关系,一些时钟在我们的设计里没有对应的端口,如下图所示:
上图中,一共用4个时钟源,有5种不同的时钟;我们要综合电路使用的是时钟CLKC,时钟源是OSC3,前后模块的时钟各不一样,因此是异步电路。
(在传统的同步和异步设计分类上,有些由同一个晶振产生的时钟由于可能没有固定的相位关系,因此会被认为是异步设计;在那种情况下,我们也可以使用这里的异步约束进行相关的时序约束)
进行异步电路设计时,设计者要注意会产生亚稳态,导致某些寄存器的输出为不定态。为了避免产生亚稳态问题,可以考虑在设计中使用双时钟、不易到亚稳态的触发器(double-clocking,metastable-hard Flip-Flops),或使用双端口(dual-port)的FIFO等等。
对于穿越异步边界的任何路径,我们必须禁止对这些路径做时序综合。由于不同时钟源的时钟之间相位关系是不确定的,一直在变,对跨时钟域的路径作时间约束是毫无意义的。因此我们不要浪费DC的时间,试图使异步路径“满足时序要求”。我们可用set_false_path命令为跨时钟域的路径作约束(其实是解除时序路径的约束)。这也就是异步电路里面的时序约束比较重要的。
例如对于下面的异步电路:
设计之间是异步的,存在垮时钟域的路径(如上图所示),我们就要用set_false_path命令为跨时钟域的路径作约束,上图的异步电路对应的跨时钟域约束如下所示:
#Make sure register-register paths meet timing
create_clock -period 20 [get_ports CLKA]
create_clock -period 10 [get_ports CLKB]
#Don't optimize logic crossing clock domains
set_false_path -from [get_clocks CLKA] -to [get_clocks CLKB]
set_false_path -from [get_clocks CLKB] -to [get_clocks CLKA]
如果设计中的所有时钟都是异步的,可用下面命令为跨时钟域的路径做约束:

用set_false_path命令对路径作时序约束后,DC做综合时,将中止对这些路径做时间的优化。
(2)逻辑上不存在的路径的约束
set_false_ path命令除了可以用于约束异步电路外,还可以用于约束逻辑上不存在的路径(logically false paths)。逻辑上不存在的路径是什么呢,下面通过一个例子说明,对于下面的电路:

当选择信号是0的时候,前面的MUX打开的是A1,后面MUX打开的是B2,因此数据的通路就是A1B2(数据从A1流到B2);当选择信号是1的时候,前面的MUX打开的是B1,后面MUX打开的是A2,因此数据的通路就是B1A2。由此可以看到,选择信号无论是1还是0,前面的MUX的A1引脚和后面的MUX的A2引脚之间是没有数据流通的,也就是该逻辑通路并不存在。同样,前面的MUX的B1引脚和后面的MUX的B2引脚之间的逻辑通路也不存在。因此这两条数据通路就是逻辑上不存在的路径,比如从点A1到点A2之间有一条物理上的连接路径,但是点A1输入信号并不通过这条路径传输到A2;这种物理上存在连接关系,但是逻辑不存在的路径称为逻辑伪路径,在DC中,伪路径“false path”称为时序例外(timing exceptions)。可以用下面的拓扑图理解:
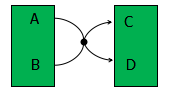

我们可以用report_timing_requirements命令报告设计中所有的例外(包括有效的例外和无效的例外)。在report_timing_requirements命令加选项"-ignored",将把无效的例外报告出来,例如:

上面的报告中,我们可以知道,从引脚{IO_PCI_CLK\pclk}到引脚{IO_SDRAM_CLK\ SDRAM_ CLK}并不存在实际的信号流通,也就是这是一条逻辑伪路径。引脚{IO_SDRAM_CLK\SDRAM_CLK}不是路径的终点(根据定义,路径的终点必须是输出端口或寄存器的数据输入引脚);引脚FF1/Q不是路径的起点(根据定义,时序路径的起点必须是输入端口或寄存器的时钟引脚)。注意:report_timing_requirements命令无”-valid”,选项。该命令的所有选项如下:

要去掉任何不要的例外,可使用reset_path命令,例如: dc_shell > reset_path -from FF1/Q
2、多时钟周期的时序约束
(1)关于建立时间
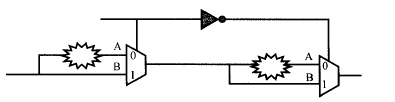
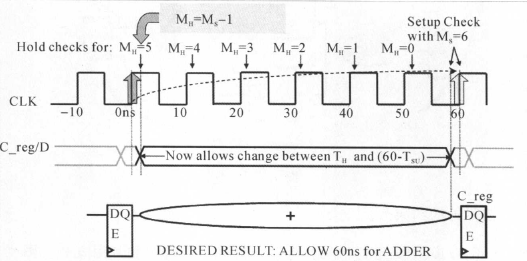
如下图所示加法器电路,时钟clk的周期定义为10ns,按设计规格,加法器的延迟约为6个时钟周期:

①默认的的建立时间约束
默认的时间建立时间约束将指示DC在10ns的时候对C_reg进行建立时间是否满足的分析;很显然,默认的时序约束会使寄存器的数据输入引脚C_reg/D信号变化,不满足建立(setup)的要求,将产生亚稳态,寄存器C_reg的输出为不定态。也就是一个时钟周期的约束不能满足约束要求。
②修改后的建立时间约束
对于多时钟周期的建立时间约束,可以使用下面命令进行修改:
create_clock -period 10 [get_ports CLK]
set_multicycle_path6-setup -to [get_pins C_reg[*]/D]
(等价于set_multicycle_path-setup 6 -to [get_pins C_reg[*]/D] )
注意这条命令是要知道多时钟周期的终点寄存器的(注意:这条命令设置了所有的前级寄存器时钟端口到C_reg寄存器的D端口路径都是多时钟周期路径,而set_multicycle_path6-setup -from A_reg/Clk -to [get_pins C_reg[*]/D],则是仅仅现在从A寄存器的时钟端口到C_reg寄存D端口的这一条路径而已),通过这条命令,就告诉DC将仅仅在第6个上升沿,即60 ns作建立的分析(也就是间隔6个时钟周期后再做建立时间分析)。这时,加法器的最大允许延迟是:

对应的时序关系如下图所示:

(2)关于保持时间
①默认的保持时间约束
对于保持时间的约束,我们是不是默认就OK了呢?在前面的建立时间和保持时间的概念中,我们知道默认的保持分析时间在建立分析的前一周期,(此处应该有链接)也就是说,在这个多时钟周期的加法器中,DC将在50 ns这个时刻分析电路有无违反保持要求,要求加法器的最小延时是(注意这是默认的情况下的所做的时序要求):
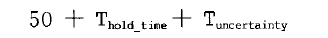
默认的保持时间分析对应的时序关系如下所示:

也就是说,经过修改过后的多时钟周期建立时间约束和默认的保持时间约束就会告诉DC,要DC综合出一条路径使其建立时间满足60 ns的要求,并且同时满足保持时间50ns的要求。
但是要综合出这样一条路径实际上是没有必要的,这样做只会增加电路的复杂度。为什么会这样呢?这是因为默认保持时间不满足约束,也就是说,不应该在50ns的时候进行保存时间的检测,需要修改多时钟周期保持时间的约束。
②修改后的保持时间约束
那在上面什么时候做保持时间分析比较合适呢?我们知道在时间为60 ns的时刻,引起寄存器C_reg的D引脚信号变化的是时钟CLK在0时刻的触发沿。此刻(在0ns时),时钟CLK把寄存器A_reg和B_reg的D引脚信号采样到它们的输出端。再通过加法器把信号传输到寄存器C_reg的D引脚。由此可见会冲掉C_reg的D端数据只是A_reg和B_reg的D引脚的变化的时候,也就0ns时刻,因此应该对保持时间做出调整,应该在0ns的时候做保持时间的检测,也就是应该提前5个时钟周期,从50ns提前到0ns。
修该后的约束如下所示:

对应的时序关系如下所示:
保持时间的分析提前了5个周期,加法器的允许延时为:
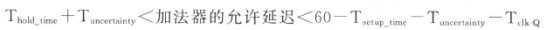
仅仅通过约束告诉DC这是一个多时钟周期的加法器电路是不够充分的,一方面是由于后面的触发器应该经过6个时钟周期之后才能采到正确的值(但是C_reg不知道什么采到的值是正确的),另一方面是约束仅仅是告诉DC如果这块电路的延时太大或者太小的时候要报错;可以这么理解,约束单单保证了时序上这个是一个多时钟周期的加法器电路,但是这个加法器电路经过延时得到结果后,后面的C_reg采样的正确性,需要在RTL代码的设计上保证,需要加上相应的控制信号,保证DC能够综合出能够正确工作的多时钟周期的加法器。对于前面的加法器,可以需要加上相应的使能信号,因此电路设计如下所示:
(3)多时钟路径和普通路径同在一个设计中
前面的例子是单纯的多时钟周期设计,当电路里面同时存在多时钟周期路径和普通路径时,如下图所示:

该电路中,要求寄存器间的乘法运算为两个时钟周期,加法运算为默认的一个时钟周期,这时候,可以使用下面命令进行约束:
create_clock -period 10 [get_ports clk];#创建时钟
set_multicycle_path -setup 2 -from FFA/CP -through Multiply/Out -to FFB/D ;
set_multicycle_path -hold 1 -from FFA/CP -through Multiply/Out -to FFB/D ;
注意电路图中的from、through、to的对象
3、分频电路和多路时钟传输的时钟约束
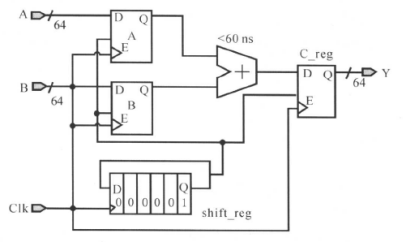
下面的电路中包含了时钟分频电路和多路时钟传输电路:
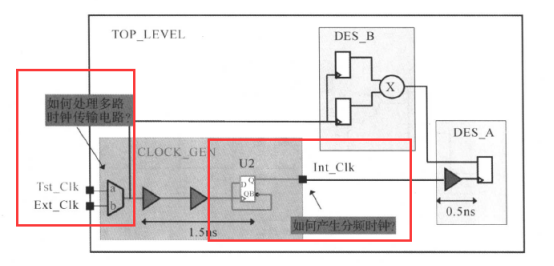
(1)首先是多路时钟的传输问题:
对于上图中的电路,其多路时钟传输电路的模型如下所示:

其内部电路的时钟(Int_Clk)连接到多路输出电路的输出,如果我们不告诉DC要用Tst_Clk、Ext_Clk中的哪一个时钟,DC会自己选择一个,这就可能出现DC选择不同的时钟做建立和保持的分析,因此我们必须指定要用哪个时钟进行约束和分析。例如对于下面的多路时钟传输电路:
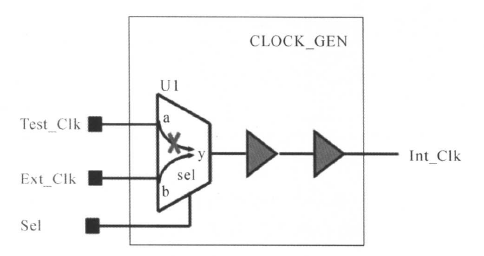
可以使用的下面命令进行约束:
create_clock Ext_Clk -period 10 (=create_clock -period 10 Ext_Clk )
create_ clock Test_Clk -period 100
set_dont_touch_network [get_clocks Ext_Clk]
set_dont_touch_network [get_clocks Test_ Clk]
#Allow DesignTime to use Ext_ Clk fortiming analysis
set_disable_timing CLOCK_GEN/U1 -from a -to y
最后一行的命令(set_disable_timing)去掉了MUX从引脚a到引脚Y的时间弧((timing arc),这时DC认为它们没有时间关系,也就是,我们只指定使用Ext_ Clk这时钟进行分析建立时间和保持时间。set_disable_timing命令用起来很灵活,该命令有多个选项。我们可以用该命令使设计中用到的库单元的时间弧(timing arc)无效。set_disable_timing命令使当前设计中的通过指定单元,引脚或端口的时间无效(相当于断开)。set_false_ path在这里不起作用。我们已经定义了Test_ Clk和Ext_ Clk为时钟,从引脚a和b到引脚Y是一条理想的时钟路径,不受约束,因此set_false_ path命令不起作用。
除了使用set_disable_timing 这条命令进行多路时钟传输的约束外,还有用模式分析特征(case analysis feature)进行约束,如下所示:
set_case_analysis 0 [get_pins U1/sel]
或者
set_case_analysis 0 [get_ports sel]
与命令set_disable_timing相比,命令set_case_analysis 会增加DC的运行时间,但使用模式分析命令较简单。
(2)接下来是分频电路:
Design Compiler不能推导出分频时钟的波形。时钟信号可以通过任何的组合电路,但中止于寄存器。DC并不知道寄存器的输出端为时钟信号或非时钟信号。如下图所示:
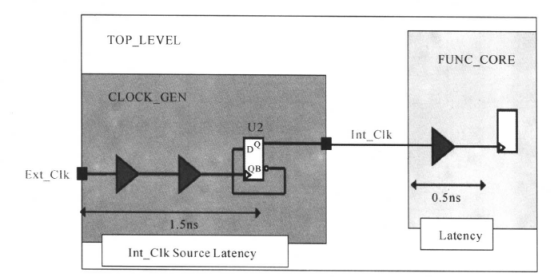
Int_Clk是Ext_Clk经过二分频后从寄存器U2的输出端口Q输出的时钟,但DC并不知道这是你的时钟信号,需要添加相应的约束,如下所示:
create_clock -period 50 [get_ports Ext_Clk] ;
create_generated_clock -name Int_Clk -source [get_pins CLOCK_GEN/U2/CP] -divide_by 2 [get_pins CLOCK_GEN/U2/Q] ;
set_clock_latency -source 1. 5 [get_clocks Int_Clk] ;
set_clock_latency 0.5 [get_clocks Int_Clk] ;
create_generated_clock这条命令会将时钟源(Ext_Clk)的任何变化自动反映在产生的时钟(Int_Clk)上。
做完版图后的设计已经加入了时钟树,连线的寄生参数也被反标(back-annotated)到时钟树上。这时候,DC用set_propagated_clock命令和时钟树的实际寄生参数自动地计算所有时钟引脚的延迟。我们不需用set_clock_latency命令为时钟建模。约束改成:
create_clock -period 50 [get_ports Ext_Clk] ;
create_generated_clock -name Int_Clk -source [get_pins CLOCK_GEN/U2/CP] -divide_by 2 [get_pins CLOCK_GEN/U2/Q] ;
set_propagated_clock [list [all_clocks] [get_generated_clock *]]
(3)多时钟发送/接收
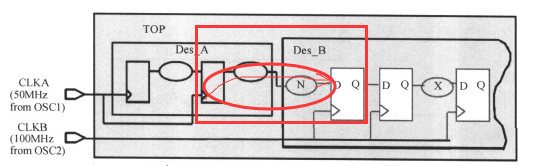
前面分别讲了多路时钟传输和分频的约束,也就把下面电路图中的阴影部分单独拿出来进行约束;将下来,将为下面的电路进行多时钟发送/接收问题(DES_B模块和DES_A模块之间存在数据的发送和接收)进行约束:

假设我们使用的Ext_Clk的时钟,其周期是50ns。模块B与模块A的时钟是有周期关系的,单单看模块A和模块B,就是多时钟同步设计的问题了,对于整个模块也就是(TOP_LEVEL),可以使用下面的约束:
create_clock -period 50 -waveform {0 25} Ext_Clk
create_clock -period 100 -waveform {0 50} Int Clk
set_clock_latency -source 1. 5 [get_clocks Int_Clk] ;
set_clock_latency 0.5 [get_clocks Int_Clk] ;
4、实战
这次的实战和以前的实战不一样,这次的实战不再是从RTL源文件开始,而是从一个被约束过的、综合过的文件,也就是经过映射后的.ddc文件,通过对编译后的设计进行合适的约束,使得设计满足设计要求。
我们先来看一下我们要进行约束的部分RTL原理图:
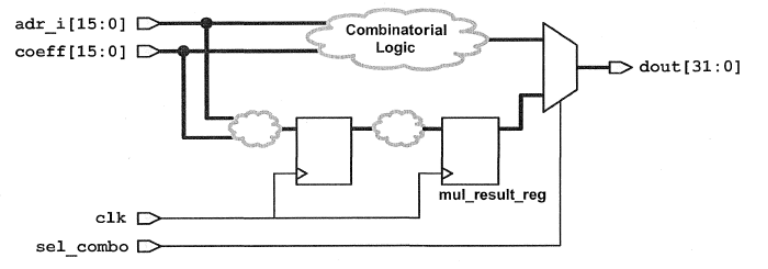
这个设计包含了纯组合逻辑、时序逻辑、多路选择器导致的伪路径。组合和逻辑和时序逻辑具有不同的约束,实验初始的约束不当,有设计违规;我们需要进行合适的约束,从而消除设计违规。
①启动DC,读入.ddc设计,进行读入设计后的检查
这步骤跟前面的章节类似,不再进行叙述,需要注意的是,因为需要读入.ddc设计,因此使用的命令是read_ddc
②查看综合后原始的违规情况:

可以知道有违规情况。
③进行合理地约束:
最初的约束不符合情况,因此在这里我们进行合适的约束(或者说重新进行约束)。
--->约束组合逻辑:
我们根据下面的原理图进行约束:
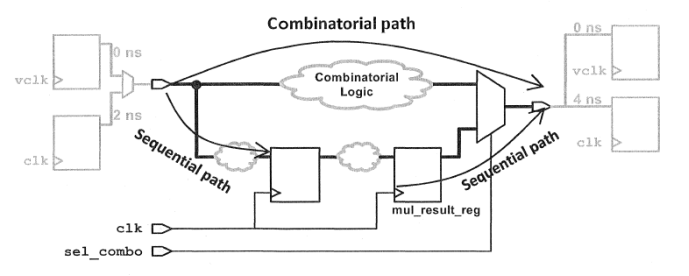
·对于组合逻辑,一方面,组合逻辑的具有6ns的最大延时;另一方面,由于组合逻辑没有时钟输入端口,因此需要创建虚拟时钟,因此第一步对组合逻辑的约束如下:
create_clock -name vclk -period 6
set in_ports [get_ports "coeff* adr_i*"]
set_input_delay 0 -clock vclk -add_delay $in_ports
set_output_delay 0 -clock vclk -add_delay [all_outputs]
·我们可以查看约束后的虚拟时钟的路径情况:
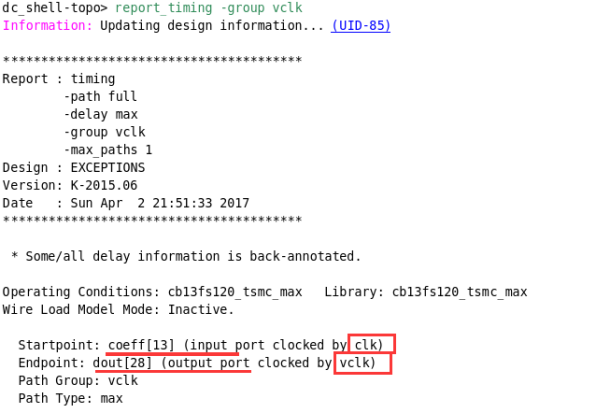
可以看到,设计依旧违规了,这是由于多路选择器的原因,clk和虚拟时钟vclk进行交叠了;因此我们要在逻辑路径上设置伪路径,禁止这些时钟进行时序分析:
set_clock_group -name false_grp1 -logically_exclusive -group clk -group vclk
设置完成之后,vclk不违规了。
·组合逻辑并没有约束完成,虚拟时钟vclk虽然不违规,但是clk违规了,对于组合逻辑,clk并没有起到作用,因此还需要禁止clk对组合逻辑的输入到输出进行时序分析:
set_false_path -from [get_clocks clk] -through $in_ports -through [all_outputs] -to [get_clocks clk]
注意,约束使用了两个“through”选项,把clk到clk的组合路径,从clk到clk的时序路径中分离出来;约束完成之后,我们可以查看一下对于组合逻辑的输入输出路径,clk的分析情况:
report_timing -from $in_ports -to [all_outputs]
结果是通过的。
--->约束多周期路径
约束完组合路径,我们就要进行约束时序逻辑路径了。时序逻辑路径是由clk控制的,我们先来看一下clk的时序路径报告:
report_timing -group clk
得到的结果是违规的,这是因为时序逻辑路径中存在多周期路径,在原理图上,mul_result_reg是多周期路径,因此需要进行设置多周期路径约束:
·建立时间的多周期约束:
set_multicycle_path 2 -setup -to mul_result_reg*/D
也就是设置这条路径是2个周期的路径;约束完成之后,我们可以查看是否正确约束:
report_timing -to mul_result_reg*/D
可以看到,建立时间的约束满足了,没有违规
·保持时间的多周期约束:
我们查看保持时间是否违规:
report_timing -to mul_result_reg*/D -delay min
可以看到,保持时间是违规的,因此我们要进行保持时间的多周期路径约束:
set_multicycle_path 1 -hold -to mul_result_reg*/D
再次查看之后,我们可以看到,保持时间没有违规了。
基于上面的原理图的各个约束都进行了合适的修改,主要是单独约束组合逻辑、设置虚假路径和设置(时序逻辑的)多周期路径这三个方面。
由于这是因为约束不当而引起综合后的违规,当设置了正当的约束之后,违规就消除了,我们也不必再进行综合了,实战步骤到这里就结束了。
本文如果有错,欢迎留言更正;此外,转载请标明出处 http://www.cnblogs.com/IClearner/ ,作者:IC_learner
概述
前面也讲了一些综合后的需要进行的一些工作,这里就集中讲一下DC完成综合了,产生了一些文件,我们就要查看它生成的网表和信息,下面就来介绍DC综合完成之后要进行哪些工作:
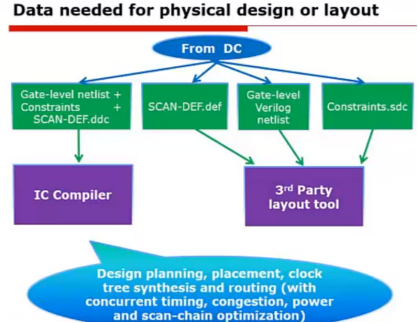

也就是说,DC一般完成综合后,主要生成.ddc、.def、.v和.sdc格式的文件(当然还有各种报告和log)
.sdc文件:标准延时约束文件:

里面都是一些约束,用来给后端的布局布线提供参考。
Scan_def.def文件:DFT、形式验证可能用到

里面包含的是一些扫描链的布局信息,需要注意的是,必须在生成ddc网表文件之前生成.def(也就先生成.def文件),以便将def文件包含在ddc文件中。
.sdf、.v文件:
标准延时格式和网表格式文件,用于后仿真。
下面是输出(生成)文件的一些命令:

1.综合网表处理与生成
(1)综合网表的处理:
完成综合并通过时序等的分析后,我们需要把设计和约束以某种格式存储好,作为后端工具的输入。
把设计以VHDL或Verilog格式存档时,需要去掉或避免文件中有assign指令,因为该指令会使非Synopsys公司的工具在读入文件时产生问题。该指令也可能会在反标( back-annotation)流程中产生问题。此外,要保证网表中没有特别的字符。例如,写出网表时,有时网表中会有反斜线符号“\”,对于这个符号,不同的工具有不一样的理解。
·assign:
多端口连线(multiple port nets)会在网表中用assign指令表示,如下图所示:

上面的设计中有冗余的端口(包括内部端口,又称层次引脚)。如果我们将设计展开(flatten), DC可能把它们优化掉,即去掉这些端口。但是如果我们不展开设计,将得到下面的结果:
Output Reset_AluRegs,Latch_Instr,....
assign Reset_AluRegs=Latch_Instr;
多端口连线,即一条连线连接多个端口,三种类型:直通连线(Feedthroughs),即从输入端直接到输出端;连线驱动多个端口(也就是上面的那个情况);常数连线驱动多个端口。
在默认的情况下,如遇到上述的情况,DC写出网表时,会在网表产生assign指令。如果设计中有多端口连线,应该在编译过程中将它们去掉。去掉多端口连线使用下面的命令:
set_fix_multiple_port_nets -all -buffer_constants [get_designs *]
·特殊符号:
特别字符是指除数字,字母或下划线以外的任何字符。当DC写出网表时,如果遇到信号Bus[31],它会插入反斜线符号“\”,将其变为\BUS[31]。但是总线Bus[31:0」中的一个信号还用Bus[31],没有用反斜线符号,也就是说设计里面可能会遇到即使用到了Bus[31]又用到Bus[31:0]这种情况(比如一组总线网A方向走,而同时又有这组总线的最高位充当某个控制信号)。这时方括弧不是名字的一部分,它们是位分隔符。这时候,同一个信号用了两种符号串表示(也就是Bus[31]和Bus[31:0]中的第31位是同一个信号,但是却有不同的字符串表示,这是不好的,一些工具可能解读出错)。最好的办法是把设计中的反斜线符号去掉,用有效的字符代替非有效(特别)的字符。
用change_names命令可将设计中的特别字符去掉。change_names命令的其中一选项是“-rules",后面可跟用自定义的命名规则或Verilog命名规则。在DC中用define_name_rules命令来规定自定义的命名规则。例如我们可以用该命令来指定可以使用哪些字符,禁止使用哪些字符,名字的长度等。一般来说,Verilog命名规则可以处理几乎所有的特殊字符。
执行change_names命令后,它会把不允许使用的字符用允许使用的字符来代替。VHDL语言中,多维数组(multi-dimensionalarrays)使用方括弧作为字下标的分隔符(word subscript delimiters)。为了避免使用反斜线符号,先使用change_names命令把字下标的分隔符转换为下划线。如下所示:


(2)相关文件的生成
经过处理之后的网表就可以生成了,除了了网表之外,我们还可以生成时序、面积报告等,相关命令如下所示:

一个是生成.ddc文件,里面包含了很多信息。一个是生成.v的门级网表。一个是生成标准约束文件,以供后面进行布局布线提供参考。
最后,进行网表处理和生成文件的综合命令如下所示:



2.时序检查与报告的生成
最后,我们要讲检查设计报告、连接设计报告、DC综合过程中的信息报告、时序检查报告、面积检查报告等进行生成,方便我们进行检查:
# Get report file
redirect -tee -file ${REPORT_PATH}/check_design.txt {check_design };
redirect -tee -file ${REPORT_PATH}/check_timing.txt {check_timing };
redirect -tee -file ${REPORT_PATH}/report_constraint.txt {report_constraint -all_violators};
redirect -tee -file ${REPORT_PATH}/check_setup.txt {report_timing -delay_type max };
redirect -tee -file ${REPORT_PATH}/check_hold.txt {report_timing -delay_type min };
redirect -tee -file ${REPORT_PATH}/report_area.txt {report_area };
这里使用的重定位的命令redirect,意思是将后面{}中命令的执行结果保存到文件中(命令的具体用法前面有讲到,也可以通过man redirect进行查看)
(1)时序报告的查看:
下面主要介绍时序报告的检测,毕竟timing is everything。关于时序报告的查看,前面也讲得很清楚了,这里再来具体讲述一下。
Design Compiler中,常用report_timing命令来报告设计的时序是否满足目标(Check_timing:检查约束是不是完整的,在综合之前查看,要注意不要与这个混淆)。
时间报告有四个主要部分:
·第一部分是路径信息部分,如下所示:

主要报告了工作条件,使用的工艺库,时序路径的起点和终点,路径所属的时钟组,报告的信息是作建立或保持的检查,以及所用的线负载模型。
·第二部分是路径延迟部分,
这个路径延迟部分是DC计算得到的实际延迟信息;命令执行后,对于下图中的路径,得到的一些路径信息,有了单元名称(point),通过该单元的延时(Incr),经过这个单元后路径的总延时等信息:
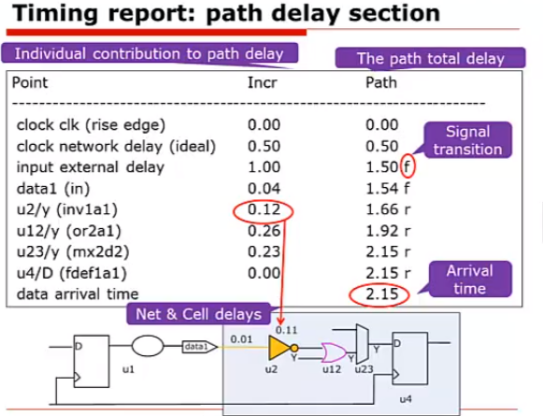
上图的解释:
路径的起点是上一级D触发器的的时钟端。
input external delay:(由于上一级D触发器的翻转(路径的起点也就这里)、芯片外部组合逻辑而经历的)输入延时约束(set_input_delay),也就是数据到达芯片的数据输入管脚的延时建模,这个延时是1ns;”r”表示上升延时,”f”表示下降延时
clock network delay(idle):时钟信号从芯片的端口到内部第一个寄存器的延时是0.5ns;
Data1(in):芯片输入端口到芯片内部真正数据输入端之间的线延时,是0.04ns。(可以认为是管脚的延时)
U2/y : 这里,前面0.12表示u2这个器件的翻转/传输延时,意思是从这个器件的数据输入端(包括连线),到输出端y的延时是0.12ns。后面的1.66的意思是从路径起点到u2的y输出的延时是1.66ns.
...
最后u4/D:这里就是终点了,D触发器的数据输入端;当然终点也可能是芯片的输出端口。
报告中,小数点后默认的位数是二,如果要增加有效数(字),在用report_timing命令时,加上命令选项“-significant_digits"。报告中,Inc:是连线延迟和其后面的单元延迟相加的结果。如要分别报告连线延迟和单元延迟,在使用report_timing命令时,加上命令选项"-input_pins"。
·第三部分是路径要求部分,如下图所示:
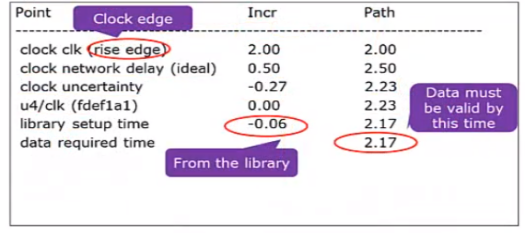
这个路径要求部分是我们约束所要求的部分;值-0. 06从库中查出,其绝对值是寄存器的建立时间。值2.17为时间周期加上延时减去时钟偏斜值再减寄存器的建立时间(假设本例中的时钟周期是2 ns)。
·第四部分是时间总结部分,如下图所示:

DC得到实际数据到达的时间和我们要求的时间后,进行比较。数据要求2.17ns前到达(也就是数据延时要求不得大于2.17ns),DC经过计算得到实际到达时间是2.15ns,因此时序满足要求,也就是met,而不是时序违规(violation)。时间冗余(Timing margin),又称slack,如果为正数或‘0',表示满足时间目标。如果为负数,表示没有满足时间目标。这时,设计违反了约束(constraint violation)。
(2)timing_report的选项与debug
在进行静态时序分析时,report_timing是常用的一个命令,该命令有很多选项,如下所示(具体可以通过man进行查看):


我们可用report_timing的结果来查看设计的时序是否收敛,即设计能否满足时序的要求。我们也可以用其结果来诊断设计中的时序问题,对于下面的报告,
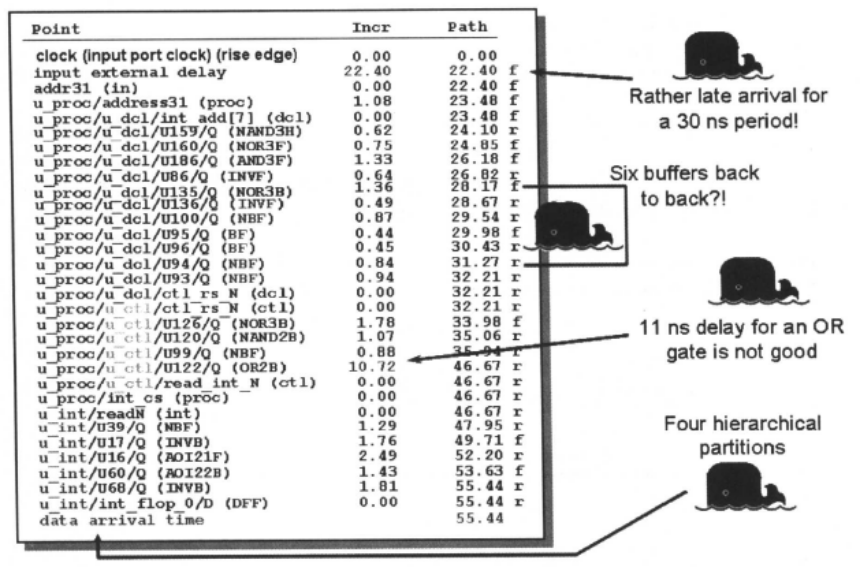
外部的输入延迟为22 ns,对于时钟周期为30 ns的设计,显然是太大了。设计中,关键路径通过6个缓冲器,需要考虑这些缓冲器是否真的需要;OR单元的延迟为10. 72ns,似乎有问题。关键路径通过四个层次划分模块,从模块u_proc,经模块u_proc/u_dcl,经模块u_proc/u_ctl,到模块u_int。前面我们说过,DC在对整个电路做综合时,必须保留每个模块的端口。因此,逻辑综合不能穿越模块边界,相邻模块的组合逻辑并不能合并。这4个层次划分模块使得DC不能充分使用组合电路的优化算法对电路进行时序优化,是否考虑需要进行模块的重新划分。
(3)设计违规检查:

当然有时候并不是真正的设计违规,有可能是约束设计过紧,有可能是设计的输入延时太紧导致violation,比如前面那个实战中,综合得到的结果是可以满足要求的,但是由于约束不当而导致DC爆出违规。
(4)查看分组优化结果:
主要是查看路径分组之后,路径的时序情况是什么样的,如下所示:

本节的基本内容就是这样了,本节就没有什么实战之类了。
本文如果有错,欢迎留言更正;此外,转载请标明出处 http://www.cnblogs.com/IClearner/ ,作者:IC_learner
本文将描述在Design Compliler中常用到的命令,这些命令按照流程的顺序进行嵌套讲解,主要是列举例子;大概的讲解布局如下所示:

大概有11个部分,下面我们逐个部分进行(简单的)介绍的举例。
1、tcl的命令和结构
tcl的命令和结构请参照第二节的内容:
http://www.cnblogs.com/IClearner/p/6617207.html ,下面是简单的常用举例。
--> 设置变量命令: set PER 2.0
显示变量命令: echo $PER # Result: 2.0
--> 表达式操作:
set MARG 0.95
expr $PER * $MARG
# expr: *, /, +, >, <, =, <=, >=
set PCI_PORTS [get_ports A]
set PCLPORTS [get_ports “Y??M Z*”]
-->命令嵌套,显示命令中嵌套表达式命令:
echo “Effctv P = [expr $PERIOD * $MARGIN]”
# Result with soft quotes: “Effctv P = 1.9”
等价于:
echo {Effctv P = [expr $PERIOD * $MARGIN]}
# Result with hard quotes:
# “Effctv P = [expr $PERIOD * $MARGIN]”
-->tcl的注释行:# Tcl Comment line
set COMMENT injine ; # Tel inline comment
-->设置tcl中的列表变量:
set MY_DESIGNS “A.v B.v Top.v”
查看列表变量:
foreach DESIGN $MY_DESIGNS {
read_verilog $DESIGN
}
-->for循环:
for { set i 1} { $i < 10 } { incr i} {
read_verilog BLOCK_$i.v
}
2、获取帮助
-->在dc_shell 中能用的命令:
pwd 、 cd 、 Is、history、 !l 、 !7 、 Ireport 、
sh <LINUX_command> :加上sh后,可以执行在linux中执行的命令,如sh gvim xxx.v & (&是后台运行)、
printenv、
get_linux_variable <LINUX_variable>
-->在dc_shell中寻求帮助:
下面的这些man、printvar命令都只能在dc_shell中运行:
help -verbose *clock :列出与*clock有关的选项
create_clock -help :查看create_clock这个命令的简单用法
man create_clock :查看create_clock这个命令的详细信息
printvar Mibrary :查看 Mibrary这个变量的内容
man target_library :查看target_library这个命令的详细信息
-->linux关联DC中的帮助,获取更多的帮助
为了能够在linux中使用dc_shell中的man命令,或者说能在linux中查看某些dc的命令,可以使用关联(alias):
$ alias dcman “/usr/bin/man -M $SYNOPSYS/doc/syn/man”
然后我们就可以使用dcman来参看dc中的命令了,例如:
$dcman targetjibrary
3、tcl语法的检查
当在DC可以执行tcl文件,在运行之前,我们要检查这个tcl文件是否有语法错误,可以使用下面的命令:
$dcprocheck xxx.tcl
4、设计对象的操作
关于设计对象的内容(比如上面是设计对象等),请查看前面的章节,这里我们只进行说对设计对象操作的一些命令(这些命令可以在dc_shell 中执行,或者写在tcl文件中)。
-->获取设计对象
get_ports 、get_pins 、get_designs 、get_cells 、get_nets 、get_clocks 、get_nets -of_objects [get_pins FF1_reg/Q] 、get_libs <lib_name> 、get_lib_cells <lib_name/cell_names> 、get_lib_pins <lib_name/cell_name/pin_names>
-->设计对象(的集合):
设计对象的物集,总之就是多个设计对象(组成一个集合)
all_inputs 、all_outputs 、all_clocks 、all_registers 、all_connected 、all_fanin 、all_fanout 、all_ideal_nets
-->对设计对象的操作:
获取设计对象(get_ports pci_*)后赋予给变量PCI__PORTS:
set PCI__PORTS [get_ports pci_*]
echo $PCI__PORTS # -≫ _sel184
查询设计对象:
query_objects $PCI__PORTS # -> {pci_1 pci_2 ...}
获取设计对象的名字:
get_object_name $PCIMPORTS # -> pci_1 pci_2 ...
获取设计对象物集的大小:
sizeof_collection $PCI_PORTS # -> 37
往设计对象物集里面增加设计对象:
set PCI_PORTS [add_to_collection $PCI_PORTS [get_ports CTRL*]]
从设计对象物集里面减少设计对象:
set ALL_INP_EXC_CLK [remove_from_collection [alljnputs] [get_ports CLK]]
比较设计对象:
compare_collections
设计对象的索引:
index_collection
分类设计对象:
sort_collection
循环查看(进行遍历)设计对象物集的内容:
foreach_in_collection my_cells [get_cells -hier * -filter “is_hierarchical == true”] {
echo “Instance [get_object_name $cell] is hierarchical”
}
过滤运算符:
# Filtering operators: ==, !=, >, <, >=, <=, =~, h
filter_collection [get_cells *] “ref_name AN*”
get_cells * -filter “dontjouch == true”
get_clocks * -filter “period < 10”
列出所有单元属性并将输出重定向到文件:
# List all cell attributes and redirect output to a file
redirect -file cell_attr {list_attributes -application -class cell}
Grep以dont_为开头的单元属性文件:
# Grep the file for cell attributes starting with dont_
$grep dont_ cell__attr | more
列出属性为dont_touch的单元名字:
# List the value of the attribute dont_touch
get_attribute <cell_name> dont_touch
识别当前设计集中的胶合单元(GLUE_CELLS):
# Example: Identify glue cells in the current design
set GLUE_CELLS [get_cells *-filter “is_hierarchicai == false”]
5、启动环境的配置
这些设置主要是在.synopsys_dc.setup文件中;或者在common_setup.tcl和dc_setup.tcl文件中,然后.synopsys_dc.setup文件把这两个文件包含。
·common_setup.tcl文件中:
set ADDITIONAL_SEARCH_PATH “./libs/sc/LM ./rtl ./scripts”
set TARGET_LIBRARY_FILES sc_max.db
set ADDL_LINK_LIBRARY_FILES IP_max.db
set SYMBOL_LIBRARY_FILES sc.sdb
set MW_DESIGN_LIB MY_DESIGN_LIB
set MW_REFERENCE_LIB_DIRS “./libs/mw_lib/sc ./libs/mw_libs/IP”
set TECH_FILE ./Iibs/tech/cb13_6m.tf
set TLUPLUS_MAX__FILE ./Iibs/tlup/cb13_6m_max.tluplus
set MAP FILE ./Iibs/tlup/cb13_6m.map
·dc_setup.tcl文件中:
#库的设置:
set_app_var search_path "$search_path $ADDITIONAL_SEARCH_PATH"
set_app_var target_library $TARGET_LIBRARY_FILES
set_app_var link_library "* $target_library $ADDL_LINK_LIBRARY_FILES"
set_app_var symbol_library $SYMBOL_LIBRARY_FILES
set_app_var mw_reference_library $MW_REFERENCE_LIB_DIRS
set_app_var mw_design_library $MW_DESIGN_LIB
get_app_var -list -only_changed_vars *
#如果存在Milkyway design库,那就不创建;否则创建Milkyway design库
if {![file isdirectory $mw_design Jibrary ]} {
create_mw_lib -technology $TECH_FILE -mw_reference_library $mw_reference_library $mw_design_library
}
open_mw_lib $mw_design_library
check_library
set_tlu_plus_tiles -max_tluplus $TLUPLUS_MAX_FILE -tech2itf_map $MAP_FILE
check_tlu_plus_files
history keep 200
set_app_var alib_library_analysis_path ../ ; # ALIB files
define_design_lib WORK -path ./work
set_svf <myjilename.svf>
set_app_var sh_enable_page_mode false
suppress_message {LINT-28 LINT-32 LINT-33 UID-401}
set_app_var alib_library_analysis_path [get_unix_variable HOME]
alias h history
alias rc “report_constraint -all_violators”
6、DC的启动方式(举例)
$dc_shell -topographical #交互式启动
dc_shell-topo> start_gui #启动图形化界面
dc_sheli-topo> stop_gui #停止图形化界面
$design_vision -topographical #启动图形化界面的同时,调用拓扑模式
$dc_shell -topo -f dc.tcl | tee -i dc.log #批处理模式
7、读入设计
有下面这些读入情况:
·read_db library_file.db
·read_verilog {A.v B.v TOP.v}
·read_sverilog {A.sv B.sv TOP.sv}
·read_vhdl {A.vhd B.vhd TOP.vhd}
·read_ddc MY_TOP.ddc
·analyze -format verilog {A.v B.v TOP.v}
elaborate MY_TOP -parameters “A_WIDTH=8, B__WIDTH=16”
然后是读入设计后的一些必要操作:
设置顶层设计:
current_design MY_T0P
检查是否缺失子模块:
link
检查设计:
if {[check_design] ==0} {
echo “Check Design Error”
exit #检查出错,退出DC
}
写出读入后的未映射设计:
write_file -f ddc -hier -out unmappedd/TOP.ddc
8、(环境、设计、时序等的)检查和移除
reset_design
report_clock
report_clock -skew -attr
report_design
report_port -verbose
report_path_group
report_timing
report_timing_requirements -ignored
report_auto_ungroup
report_interclock_relation
check_timing
reset_path -from FF1_reg
remove_clock
remove_clockJransition
remove_clock_uncertainty
remove_input_delay
remove_output_delay
remove_driving_cell
list_libs
redirect -file reports/lib.rpt {report_lib <libname>}
report_hierarchy [-noleaf]
# Arithmetic implementation and resource-sharing info
report_resources
# List area for all cells in the design
report_cell [get_cells -hier *]
check_design
check_design -html check_design.html
sh firefox check_design.html
report_constraint -all_violators
report_timing [ -delay <max | min> ]
[ -to <pi n_port_clockJ ist> ]
[ -from <pin__port_clock_list> ]
[ -through <pin_port_list> ]
[ -group]
[ -input__pins ]
[ -max_paths <path_count> ]
[ -nworst <paths_per_endpoint_count >]
[ -nets ]
[ -capacitance ]
[ -significant_digits <number>]
report_qor
report_area
report_congestion
9、约束的设置和执行
·预算估计:
如果实际输出负载值未知,则用于“负载预算”。找到库中最大的max_capacitance值,并将该值作为保守的输出负载。
set LIB_NAME ssc_core_slow
set MAX_CAP 0
set OUTPUT_PINS [get_lib_pins $LIB_NAME/*/* \
-filter "direction == 2"]
Foreach_in_collection pin $OUTPUT_PINS {
set NEW_CAP [get_attribute Spin max_capacitance]
if {$NEW_CAP > $MAX_CAP} {
set MAX_CAP $NEW_CAP
}
}
set_load $MAX _CAP [all_outputs]
·普通的约束:
reset_design
############# CLOCKS###################
# 默认情况下,每一个时钟都只对于一个时钟,除非设置下面的命令为真:
set_app_var timing_enable_multiple_clocks_per_reg true
#下面是时钟建模的例子:
create_clock -period 2 -name Main_Clk [get_ports Clk1]
create_clock -period 2.5 -waveform {0 1.5} [get_ports Clk2]
create_clock -period 3.5 -name V_Clk; # 这是虚拟时钟
create_generated_clock -name DIV2CLK -divide_by2 -source [get_ports Clk1] [get_pins I_DIV__FF/Q]
set_clock_uncertainty -setup 0.14 [get_clocks *]
set_clock_uncertainty -setup 0.21 -from [get_clocks Main_Clk] -to [get_clocks Clk2]
set_clock_latency -max 0.6 [get_clocks Main_Clk] ; # 这是版图之前的时钟情况
set_propagated__clock [all_clocks]; # 这是时钟树综合后的情况
set_clock_latency -source -max 0.3 [get_clocks Main_Clk]
set_clock_transition 0.08 [get_clocks Main_Clk]
############# CLOCK TIMING EXCEPTIONS ########
set_clock_group -logically_exclusive | -physically_exclusive | -asynchronous -group CLKA -group CLKB
set_false_path -from [get_clocks Asynch_CLKA] -to [get_clocks Asynch_CLKB]
set_multicycle_path -setup 4 -from -from A_reg -through U_Mult/Out -to B_reg
set_multicycle_path -hold 3 -from -from A_reg -through U_Mult/Out -to B_reg
set_input_delay -max 0.6 -clock Main_Clk [alljnputs]
set_input_delay -max 0.3 -clock Clk2 -clock_fall -add_delay [get_ports “B E”]
set_input_delay -max 0.5 -clock -network_latency_included V_Clk [get_ports “A C F”]
set_output_delay -max 0.8 -clock -source_latency_included Main_Clk [all__outputs]
set_output_delay -max 1.1 -clock V_Clk [get_ports “OUT2 OUT7]
################ ENVIRONMENT ######################
set_max_capacitance 1.2 [alljnputs]; # (这是用户自定义的设计规则约束)
set_load 0.080 [all_outputs]
set_load [expr [load_of slow_proc/NAND2_3/A] * 4] [get_ports OUT3]
set_load 0.12 [all_inputs]
set_input_transition 0.12 [remove_from_collection [all_inputs][get_ports B]]
set_driving_cell -lib_cell FD1 -pin Q [get_ports B]
与物理设计有关的约束:
create_bounds ...
create_rp_groups...
set_app_var placer_soft_keepout_channel_width...
set_app_var placer_max_cell_density_threshold...
set_congestion_options...
setjgnoredjayers...
set_aspect_ratio 0.5 # (高度和宽度的比值)
set_utilization 0.7 #(利用率)
set_placement_area -coordinate {0 0 600 400}
create_die_area -polygon {{0 0} {0 400} {200 400} {200 200} {400 200} {400 0} {0 0}}
set_port_side {R} Port__N
set_port_location -coordinate {0 40} PortA
set_cell_location -coordinate {400 160} -fixed -orientation {N} RAM1
create_placement_blockage -name Blockagel -coordinate {350 110 600 400}
create_bounds -name “b1” -coordinate {100 100 200 200} INST_1
create_site_row -coordinate {10,10} -kind CORE -space 5 -count 3 {SITE_ROW#123}
create_voltage_area -name VA1 -coordinate {100 100 200 200} INST_1
create_net__shape -type wire -net VSS -origin {0 0} -length 10 -width 2 -layer M1
create_wiring_keepouts -name "my__keep1" -layer "METAL1" -coord {12 12 100 100}
report_physical_constraints
reset_physical_constraints
约束的执行:
redirect -tee -file reports/precompile.rpt {source -echo -verbose TOP.con}
redirect -append -tee -file reports/precompile.rpt {check_timing}
如果有直接的tcl约束,那么直接约束:
source <Physical_Constraints_TCL_file>
如果没有的话,可以从物理设计中抽取:
extract_physieal_constraints <DEF_file>
read_floorplan <floorplan_cmd_file>
10、综合优化
路径分组:
group_path -name CLK1 -criticai_range <10% of CLK1 Period> -weight 5
group_path -name CLK2 -critical_range <10% of CLK2 Period> -weight 2
group_path -name INPUTS -from [alljnputs]
group_path -name OUTPUTS -to [all_outputs]
group_path -name COMBO -from [alljnputs] -to [all_outputs]
set_fix_multiple_port_nets -all -buffer_constants
综合时的选项:
# Licenses required to take advantage of all Design Compiler optimization
# features: DC-Ultra, DesignWare, DC-Extension (for DC-Graphical), DFTC
# Enable multi-core optimization, if applicable:
set_host_options -max_cores <#>
report_host__options
remove_host_options
# 防止特定的子模块被 ungrouped:
set_ungroup <top_level_and/or_pipeiined_blocks> false
# 防止DesignWare层次结构被 ungrouped:
set_app_var compile_ultra_ungroup_dw false
# 如果需要:禁用特定子设计的边界优化:
set_boundary_optimization <cells or designs> false
# 如果需要:从适应性重新定时中排除特定的单元/设计(-retime)(也就是放在某些模块或者设计的寄存器被retime移动):
set_dont_retime <cells_or_designs> true
# 如果需要:通过手动控制寄存器复制的个数
#最大扇出的情况:
set_register_replication [-num_copies 3 | -max_fanout 40] [get_cells B_reg]
# 如果需要:更改寄存器复制命名样式:
set_app_var register_replication_naming_style "%s_rep%d"
# 如果要求应用,那么就要为测试准备的综合选择扫描寄存器,并且禁止自动地移位寄存器定义:
set_scan_configuration -style <multiplexed_flip_flop | clocked_scan | lssd | aux_clock_lssd>
set_app_var compile_seqmap_identify_shift_registers false
# 如果有要求保持流水线中的寄存器器输出,就要进行约束:
set_dont_retime [get_cells U_Pipeline/R12_reg*] true
# 如果设计中包含有纯的流水线设计,那么可以进行寄存器retiming:
set_optimize_registers true -design My_Pipeline_Subdesign -clock CLK1 -delay_threshold <clock_period>
# 默认情况下,整个层次结构使用compile_ultra -spg进行拥塞优化,选择性地禁用/启用子设计上的拥塞优化:
set_congestion_optimization [get_designs A] false
# 第一次编译:根据需要启用/禁用优化:
compile_ultra -scan -retime -timing [-spg] \
[-no_boundary] \
[-no_autoungroup] \
[-no_design_rule] \
[-no_seq_output_inversion]
#根据需要,更多地关注违规的关键路径:
group_path -name <group_name> -from <path_start> -to <path_end> -critical range <10% of max delay goal> -weight 5
# 执行增量编译:
compile_ultra -scan -timing -retime -incremental [-spg]
11、综合后处理
set_app_var verilogout_no_tri true
change_names -rule verilog -hier
write_file - f verilog -hier -out mapped/TOP.v
write__file - f ddc -hier -out mapped/TOP.ddc
write_sdc TOP.sdc
write_scan_def -out TOP_scan.def
最后附上两张流程图:

 /1
/1 
 eetop公众号
eetop公众号 创芯大讲堂
创芯大讲堂 创芯人才网
创芯人才网