日志
隐私计算是什么?有什么作用?【转】
| |
https://blog.csdn.net/qq_32727095/article/details/124410579
01 隐私计算技术的起源
假设有两个百万富翁,他们都想知道谁更富有,但他们都想保护好自己的隐私,都不愿意让对方或者任何第三方知道自己真正拥有多少财富。那么,如何在保护好双方隐私的情况下,计算出谁更有钱呢?
这是2000年图灵奖得主姚期智院士在1982年提出的“百万富翁”问题。
这个烧脑的问题涉及这样一个矛盾,如果想比较两人谁更富有,两人似乎就必须公布自己的真实财产数据。但是,两个人又都希望保护自己的隐私,不愿让对方或者任何第三方知道自己的财富。在普通人看来,这几乎是一个无解的悖论。
然而在专业学者眼里,这是一个加密学问题,可以表述为“一组互不信任的参与方在需要保护隐私信息以及没有可信第三方的前提下进行协同计算的问题”。这也被称为“多方安全计算”(Secure Multiparty Computation,SMC)问题。
姚期智院士在提出“多方安全计算”概念的同时,也提出了自己的解决方案——混淆电路(Garbled Circuit)。随着多方安全计算问题的提出,投入到多方安全计算研究的学者越来越多。除了混淆电路之外,秘密共享)、同态加密等技术也开始被用来解决多方安全计算问题,隐私计算技术也逐步发展了起来。
02 隐私计算的概念
多方安全计算在20世纪80年代初提出的时候,还只是作为一种亟待可行性验证的技术理论,而后计算机算力不断提高,移动互联网、云计算和大数据等技术快速发展,催生了众多新的服务模式和应用。
这些服务和应用一方面为用户提供精准、个性化的服务,给人们的生活带来了极大便利;另一方面又采集了大量用户的信息,而所采集的信息中往往含有大量包括病史、收入、身份、兴趣及位置等在内的敏感信息,对这些信息的收集、共享、发布、分析与利用等操作会直接或间接地泄露用户隐私,给用户带来极大的威胁和困扰。
个人隐私保护成为人们广泛关注的焦点,人们也都认识到隐私信息是大数据的重要组成部分,而隐私保护关乎个人、企业乃至国家的利益。
针对隐私保护问题,学术界开展了大量的研究工作,包括多方安全计算技术在内的隐私保护技术在逐步完善发展中得以应用。然而,隐私缺乏定量化的定义,隐私保护的效果、隐私泄露的利益损失以及隐私保护方案融合的复杂性三者缺乏系统的计算模型,这就使得隐私信息在不同系统和不同用户间的共享、交换和分析过程中难以被准确刻画和量化,阻碍了各类计算和信息服务系统对隐私进行有效、统一的评价。
针对这一问题,2016年,中国科学院信息工程研究所研究员李凤华等对隐私计算在概念上进行了界定:
隐私计算是面向隐私信息全生命周期保护的计算理论和方法,具体是指在处理视频、音频、图像、图形、文字、数值、泛在网络行为信息流等信息时,对所涉及的隐私信息进行描述、度量、评价和融合等操作,形成一套符号化、公式化且具有量化评价标准的隐私计算理论、算法及应用技术,支持多系统融合的隐私信息保护。
隐私计算涵盖信息所有者、搜集者、发布者和使用者在信息采集、存储、处理、发布(含交换)、销毁等全生命周期中的所有计算操作,是隐私信息的所有权、管理权和使用权分离时隐私描述、度量、保护、效果评估、延伸控制、隐私泄露收益损失比、隐私分析复杂性等方面的可计算模型与公理化系统。
同时,中国信通院根据数据的生命周期,将隐私计算技术分为数据存储、数据传输、数据计算过程、数据计算结果4个方面,每个方面都涉及不同的技术,如图下所示。数据存储和数据传输技术相对成熟,读者也可能应用过相关技术。
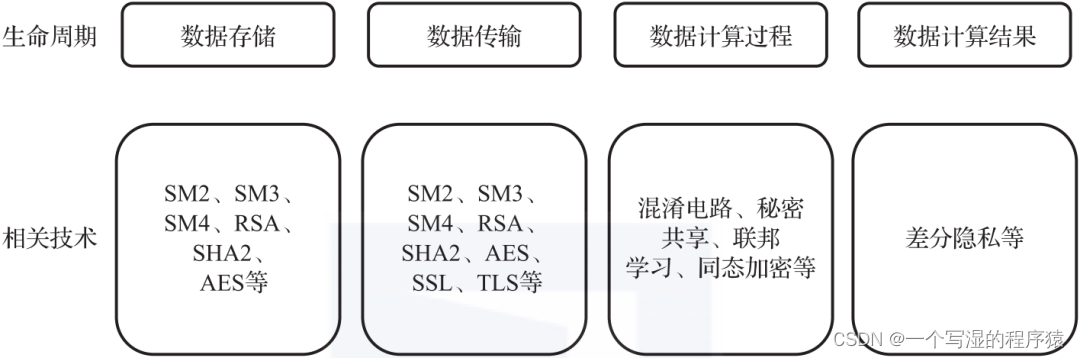
根据数据生命周期,我们可以将隐私计算的参与方分为输入方、计算方和结果使用方三个角色。
在一般的隐私计算应用中,至少有两个参与方,部分参与方可以同时扮演两个或两个以上的角色。计算方进行隐私计算时需要注意“输入隐私”和“输出隐私”。输入隐私是指参与方不能在非授权状态下获取或者解析出原始输入数据以及中间计算结果,输出隐私是指参与方不能从输出结果反推出敏感信息。

联合国全球大数据工作组将隐私保护计算技术定义为在处理和分析数据的过程中能保持数据的加密状态、确保数据不会被泄露、无法被计算方以及其他非授权方获取的技术。与之基本同义的一个概念是“隐私增强计算技术”,通常可换用。本文统一使用中文简称“隐私计算技术”。
03 隐私计算技术的发展脉络
现在,除了MPC技术外,隐私计算领域还呈现出更多新的技术特点和解决方案。目前,从技术层面来说,隐私计算主要有两类主流解决方案:
一类是:采用密码学和分布式系统;
另一类是:采用基于硬件的可信执行环境(Trusted Execution Environment,TEE)。
目前,密码学方案以MPC为代表,通过秘密共享、不经意传输、混淆电路、同态加密等专业技术来实现。近几年,其性能逐渐得到提升,在特定场景下已具有实际应用价值。基于硬件的可信执行环境方案是构建一个硬件安全区域,隐私数据仅在该安全区域内解密出来进行计算(安全区域之外,数据都以加密的形式存在)。
其核心是将数据信任机制交给像英特尔、AMD等硬件方,且因其通用性较高且计算性能较好,受到了较多云服务商的推崇。这种通过基于硬件的可信执行环境对使用中的数据进行保护的计算也被称为机密计算(Confidential Computing)。
另外,在人工智能大数据应用的大背景下,近年来比较火热的联邦学习也是隐私计算领域主要推广和应用的方法。
下图展示了各项隐私计算技术的发展时间线。可以看出,隐私计算技术还是比较“年轻”的技术。

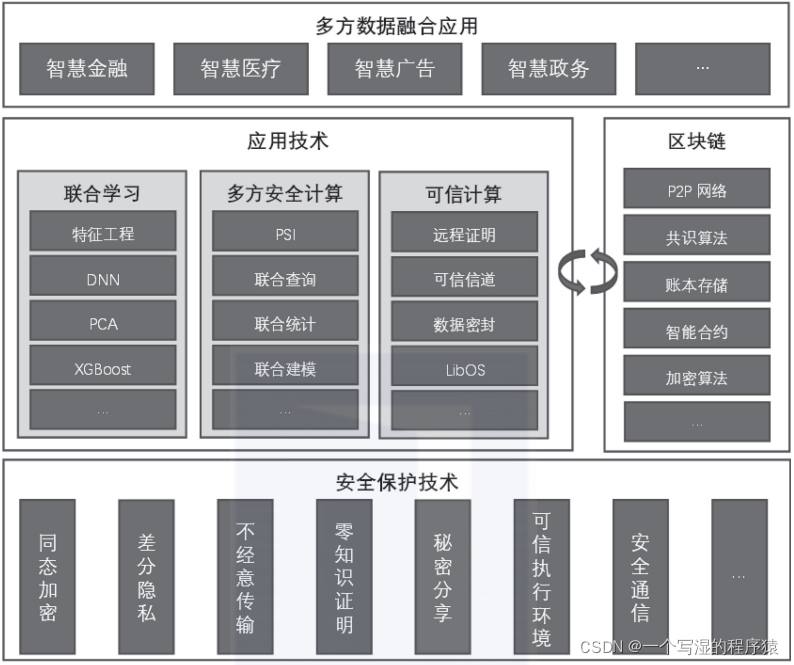
《腾讯隐私计算白皮书2021》将当前隐私计算的体系架构总结。一般而言,越是上层,其面临的情况可能越复杂,往往会综合运用下层中的多项技术进行安全防护。
04 隐私计算技术的应用场景
隐私计算技术可以为各参与方提供安全的合作模式,在确保数据合规使用的情况下,实现数据共享和数据价值挖掘,有着广泛的应用前景。目前,隐私计算技术的应用场景还在不断扩展。
1. 金融行业
在金融行业,数据渠道融合与风险控制是业务实施的重要部分。作为数据隐私安全的重要保障,隐私计算技术在金融领域的应用前景广阔。
隐私计算技术可以应用于金融行业的获客和风控,比如多家金融机构在不泄露客户个人信息的前提下对客户进行联合画像和产品推荐;在多头借贷等场景下,在不泄露客户已有贷款数额、各金融机构所拥有的黑名单等信息的前提下有效评估客户的信用情况,降低违约风险。
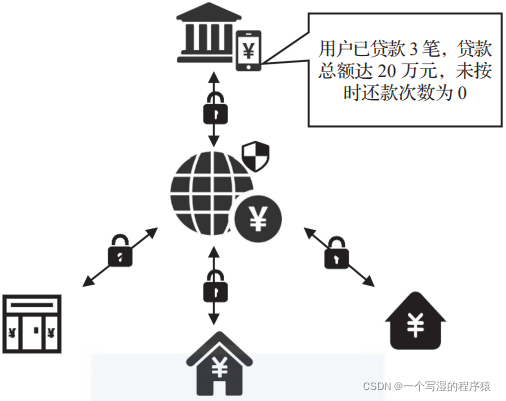
以征信系统为例,银行、小贷公司等金融机构需要通过多个信息渠道对潜在用户的历史记录进行多维度计算分析。但由于这些数据具有很高的隐私性,且很多信息渠道并不具备足够安全可靠的信息传输管控技术,征信系统的数据丰富性不足或者维度缺失。
如下图所示,通过隐私计算中的多方安全计算技术,各金融机构、信息渠道可形成征信系统联盟,各方数据无须离开本地就能提供数据分析服务。
2. 医疗健康行业
在医疗健康行业,利用人工智能技术针对病情与病例数据建立机器学习模型并训练,可以提高医疗科研与病情推断的效率,提升医疗服务的精准度。
但是由于之前缺乏统筹规划和顶层设计,各地医院的信息系统独立且分散;同时,由于医疗数据属于极度隐私的信息,为了避免出现合规风险,各医疗机构普遍对数据持保守态度,病情与病例数据不允许离院共享,各医疗渠道信息的数据融合难度极大,阻碍了医疗系统的智能化发展。
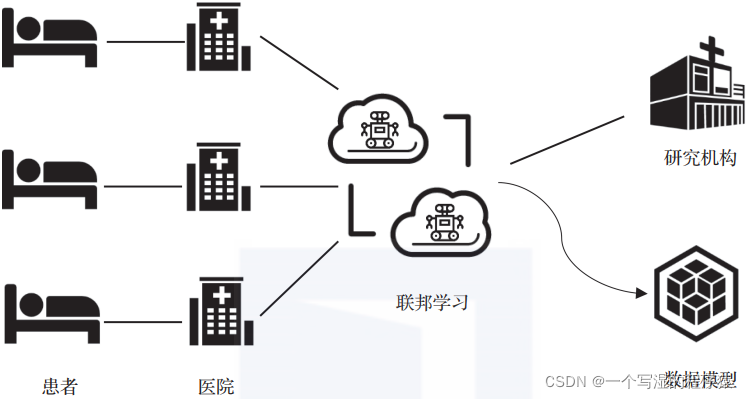
隐私计算技术能够保护数据隐私,有望打破医疗数据孤岛现象,在医疗行业大有可为。比如利用隐私计算中的联邦学习技术,各医疗机构可实现在原始数据不离院的情况下进行联合建模,如图1-6所示。事实上,在医疗健康领域,隐私计算技术已经逐步落地。
3. 政务行业
在政务行业,随着数字经济的发展,智慧城市与政务大数据逐步深入人心,各地政府不断加强推动大数据的规划设计,多地政府设立大数据发展局、大数据管理局等相关管理机构。
政务数据涉及医保、社保、公积金、税务、司法、交通等方方面面,隐私安全尤为重要,如能利用隐私计算技术打通政务数据、挖掘数据潜能,那么智慧城市建设必将如虎添翼。
举例来说,隐私计算技术可以提供政府数据与电信企业、互联网企业等社会数据融合的解决方案,比如可以联合多部门的数据对道路交通状况进行预判,实现车辆路线导航的最优规划,减缓交通堵塞。目前,在一些地方政府的相关规划里,隐私计算技术有望成为下一个应用推广的重点。
未来,隐私计算技术将广泛应用于金融、保险、医疗、物流、汽车等众多拥有隐私数据的领域,在解决数据隐私保护问题的时候,也帮助解决行业内数据孤岛问题,为大量AI模型的训练和技术落地提供一种合规的解决方案。

 /1
/1 

 eetop公众号
eetop公众号 创芯大讲堂
创芯大讲堂 创芯人才网
创芯人才网