日志
Cracking Digital VLSI Verification Interview 第二章
热度 1| |
欢迎关注个人公众号摸鱼范式,后台回复pdf获得全文的pdf文件

RSIC:精简指令集。CISC:复杂指令集
RISC结构具有比较少的指令,这些指令是简单的指令(固定长度的指令和较少的寻址模式)。CISC结构具有更多的指令,更加复杂,可变长度指令和更加多的寻址方式
RISC具有较小的指令,硬件上相对没有那么复杂。CISC使用更加复杂的硬件来解码和分解复杂的指令。因此RISC更加侧重软件,CSIC更加侧重硬件
CISC具有更加复杂的指令,因此可以使用更加少的RAM来存储编程指令。相对的,RISC需要更加多的RAM来存储指令
RISC的指令通常需要一个周期完成,而CISC可以能需要多个周期才能完成,具体取决于指令的复杂性。因此在RISC中可以进行流水线化。
RISC通过减少每条指令的周期数来提高性能,而CISC通过减少每条程序的指令数来提高细嫩那个。CISC支持单条指令完成从内存读取,执行操作,写回内存的操作(mem2mem操作)。而RISC完成则需要三个指令。
冯诺依曼结构中,指令和数据存储在同一个存储器中。cpu读取数据和指令使用同一条总线,具有存储数据和指令的统一缓存。
哈佛结构中,数据和指令是分开存储的,可以使用两条不同的总线同时访问数据和指令,指令和数据都具有单独的缓存。
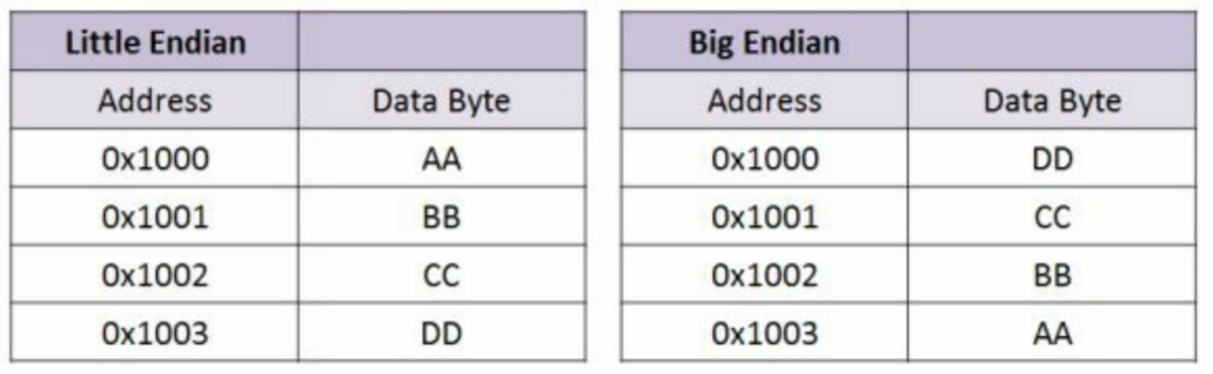
字节顺序是指字节在内存中的存储顺序。数据在内存中通常是按照字节寻址的,但是大多数计算即通常采用32位(4个字节)存储操作数的。因此,为了将一个字节存在存储器中,由两种方式:
高字节存在低地址中,这称之为Big Endian
低字节存在低地址中,这称之为Little Endian
例如,当cpu向地址0x1000中写入0xDDCCBBAA时,两种方式就会出现差异
DRAM:Dynamic Random Access Memory。动态随机存储,数据以电荷的形式存储,每个存储单元是由晶体管和电容组成的,数据存在电容中。DRAM是易失性设备,电容会因为漏电而流失电荷,所以需要定时刷新。
SRAM:Static Random Access Memory。静态随机存储,不需要属性,只需要电源即可,SRAM的存储单元由六个晶体管组成,因此与DRAM相比,占用面积更加多。
SRAM速度快,成本搞,常用于高速缓存。DRAM密度小,速度慢,常用于主存储器
[34] 对于256KB的内存,如果按字节寻址,需要多少位的地址线?256KB=2^8*2^10Bytes,需要18位地址线
[35] CPU中不同类型的寄存器有什么区别?Program Counter (PC):保存当前正在执行的指令的地址
Instruction Register (IR):保存当前正在执行的指令的寄存器。(PC所指向的地址上的值)
General Purpose Registers:通用寄存器是用于存储程序所需要的数据,通用寄存器的数量由体系结构定义,并可以由软件用于运行期间零是存储数据。
Stack Pointer Register (SP):堆栈指针寄存器用于存储压入队长的最新数据的地址。常见的用途是存储子函数调用时的返回地址。
流水线技术是在单个处理器中实现指令集并行的技术。将基本的指令周期拆分为多个阶段,无需等待每条指令完成,并行执行不同的步骤,在一条指令结束之前开始下一条指令。流水线能投提高指令的吞吐率,但是并不能减小指令的指令时间。
[37] 什么是pipeline hazard?处理器中有几种pipeline hazard?pipeline hazard是指由于某些原因下一条指令无法执行的情况。有三种类型的hazard:
Structural Hazards:由于硬件资源不足产生的。比如如果设计结构中只有一个浮点执行单元,每次执行都需要两个周期的时间,那么当程序中出现背靠背的浮点指令时会导致流水线停止。除此之外内存和缓存的访问也会导致Structural Hazards
Data Hazards:由于前后指令数据的依赖性而造成的hazard
A、RAW:先读后写register,ture data dependence
B、WAW:先写后写register,output data dependence
C、WAR:先写后读register, anti-data dependence
Control Hazards:当碰到跳转指令时,processor会stall一个cycle。
因为processor在处理指令时会分两个stage:取指令和解码指令。
当一条指令进入到解码阶段时,才会被发现需要跳转,所以在取指令阶段
的那条指令会被废掉,故浪费掉一个cycle。
Structural Hazards:将一个function unit切分成更小的stage或对设计相同功能的硬件等,总之,就是让硬件资源够用。
Data Hazards:A情况是真正的数据依赖,会产生hazard,可以用forwarding技术来减少或消除它;而B和C是在当指令顺序被compiler或者是硬件调整后才会出现的数据依赖。如果出现了B和C的情况,可以有一种技术来消除它,叫做register renaming。
Control Hazards:可以在program中加入likely()or unlikely()来帮助compiler预测taken or not taken的可能性。另外,compiler可以通过delayed-branch的技术来消除branch hazard,但是该技术很少用在很长的pipeline中。最后,可以通过硬件的技术消除Brach hazard。以上的技术都是compiler或hardware的技术,programmer可以不关心,但好的if语句应该
如下:
第一个数据需要10ns完成,此后1ns完成一个数据的处理,因此总时间位10+99=109ns
[40] 指令有多少种寻址方式?立即数寻址,操作数作为指令的一部分
直接寻址,操作数的地址直接出现在指令中
寄存器寻址,操作数被存在寄存器中,寄存器的名字出现在指令中
偏移量寻址,操作数的地址由一个寄存器的数据加上一个立即数的偏移量得到
局域性原理:程序常常重复使用它们最近用过的数据和指令。一条广泛适用的经验规律是:一个程序90%的执行时间花费在仅10%的代码中。局域性意味着我们可以根据一个程序最近访问的指令和数据,比较准确地预测它近期会使用哪些内容。局域性的原理也适应于数据访问,不过不像代码访问那样明显。
时间局域性是指最近访问过的内容很可能会在短期内被再次访问。
空间局域性是指地址相互临近的项目很可能会在短时间内都被用到。
Register
Cache
Main Memory/Primary Memory
Secondary Memory (Magnetic/Optical)
cache是小型的快速存储。通常在Main Memory和CPU之间,有时放置于CPU内。
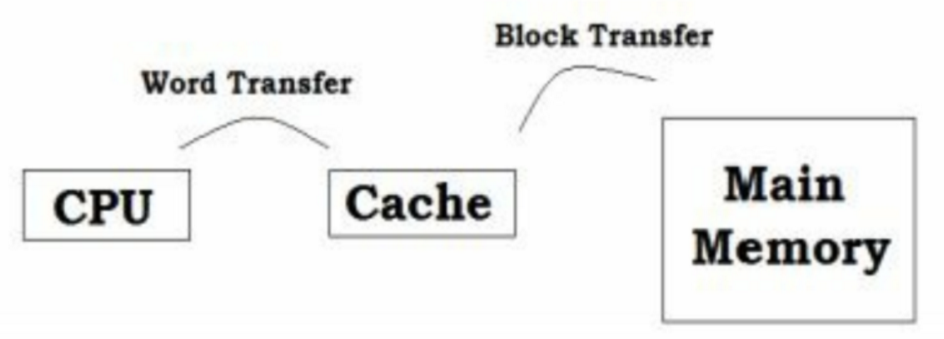
每当CPU请求存储位置的内容时,都会首先检查cache中是否有此数据。如果cache中存在数据,则CPU直接从cache中获取数据。 由于不需要CPU进入该数据的Main Memory,因此速度更快。 如果缓存中不存在数据,则将一块数据从Main Memory读取到cache中,然后以字块的形式从cache中传输到CPU。
[45] 什么是cache的miss和hit?在cache中查找地址时,若缓存中包含该内存位置,称之为cache hit。如果在cache找不到,则称之为cache miss。
[46] 如果一台机器存在cache,那么在链表和向量中搜索一个值的性能表现有什么差异?链表是一种将其元素存储在非连续存储位置中的数据结构,而向量是一种将元素存储在连续位置中的数据结构。 对于具有cache的设计:如果cache中存在一块数据,则很可能在cache中也存在后续的连续数据,因为通常是从主存储器到高速缓冲存储器的任何取指令 根据缓存行(通常为64或128字节)获取。 因此,在拥有cache的机器上,通过向量进行搜索将比链表进行搜索更快。
[47] 将内存映射到cache有哪些机制?请比较他们的优缺点一共有三种主要的映射方法。这三种映射中,主存储器和cache都被划分为存储块(blocks of memory,也称cache line,每个64bytes),这是映射时的最小单位。
直接映射(Direct Mapping):直接映射中,主内存和cache中始终存在一对一的映射,一组只有一个数据块。例如:在下图中,cache大小为128个块,而主内存中有4096个块。设计实现是基于模数计算得到的,i为cache的块序号,j是主内存的块编号,m是cache的行数,i = j mod m。如果块的大小为64B而地址为32为,则地址[5:0]称为字节偏移量,它说明字节在块中的位置,地址[12:6]称为组位,说明地址地址映射到哪一组,剩下的地址位作为标志位,标志说明cache映射了哪些内存中的地址。这是最简单的映射,并且可以通过内存地址可以轻松计算cache中的数据在内存中的位置,并且只需要一个标记为进行比较就能知道是否命中。这种映射的缺点是命中率低, Cache的存储空间利用率低。
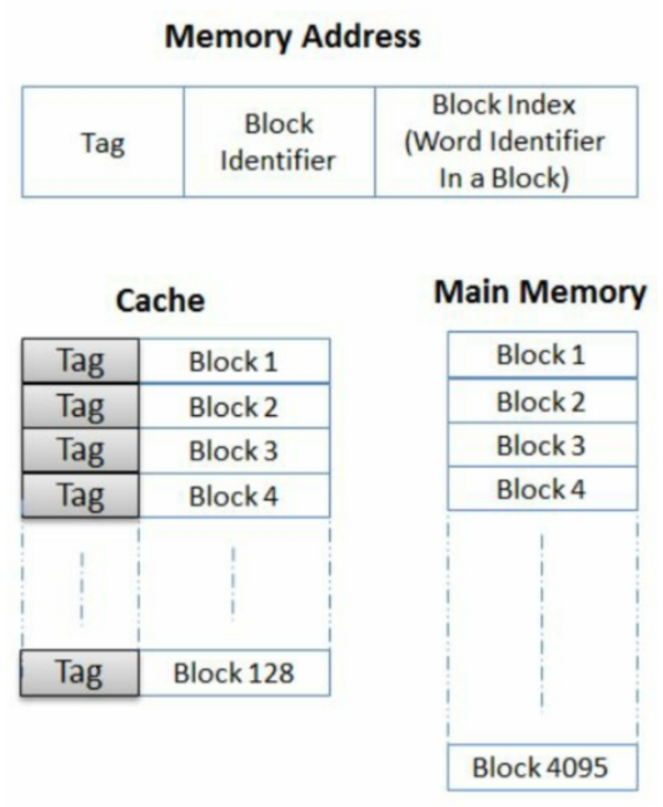
全局关联映射(Fully Associate Mapping):任何的内存块都能映射到cache的任何块中,使用和上面的图一样的例子,地址[5:0],作为块内部的索引,剩下的所有位都用于和cache中的所有标记为进行比较,这需要很大的比较器。虽然这种方式命中率较高,Cache的存储空间利用率高,但是线路复杂,成本高,速度低
组关联映射(Set Associate Mapping):将cache分成u组,每组v行,主存块存放到哪个组是固定的,至于存到该组哪一行是灵活的,即有如下函数关系:cache总行数m=u×v,组号q=j mod u组间采用直接映射,组内为全相联。例如,下图显示了128个块的相同高速缓存,这些高速缓存组织为64个集合,每个集合具有2个块。硬件较简单,速度较快,命中率较高,但是与分组有关系。
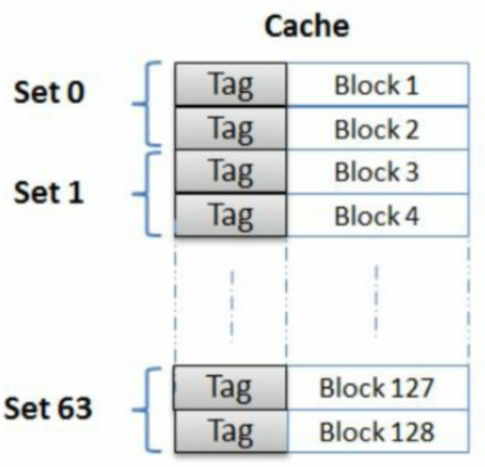
更高关联性的cache意味着需要更加大的比较器,用于将传入的地址和标签进行对比,会导致更加大的硬件需求和功耗。
[49] 一个按字节寻址的CPU的cache具有以下特征:a)与大小为1byte的块直接映射 b)块的cache索引位4位。那么cache中包含多少个块,作为cache的一部分,需要存储多少个标记为?cache的索引位有4位,因此cache包含2^4=16个块,每个块只有1byte所以不需要块内索引,剩下的16-4=12位全部作为标记位
[50] 一个四路组关联的cache总大小为256KB,如果每个cache line的大小为64byte,那么cache中有多少组?标记位需要多少位?假设地址位宽位32位。cache的块的数量为256K/64=4096,而cache为四路关联,则组数量为4096/4=1024。64byte的cache line 需要6位进行块内索引,10位进行集合索引,剩下的32-6-10=16位作为标记为
[51] 直写式缓存和回写式缓存有什么区别?优缺点是什么?直写式缓存方式: 当CPU要将数据写入内存时,除了更新缓冲内存上的数据外,也将数据写在SDRAM中以维持主存与缓冲内存的一致性,当要写入内存的数据多起来的话,速度自然就慢了下来.
回写式缓存方式: 当CPU要将数据写入内存时,只会先更新缓冲内存上的数据,随后再让缓冲内存在总线不塞车的时候才把数据写回SDRAM,所以速度自然快得多
回写缓存在内存带宽利用方面更好,因为仅在需要时才回写数据。 如果系统中存在多个可以缓存同一地址的cache,则维护数据一致性非常复杂,因为内存可能并不总是具有最新数据。
[52] inclusive 和 exclusive cache之间有什么区别?cache的inclusive和exclusive属性适用于具备多级缓存的设计。
当CPU试图从某地址load数据时,首先从L1 cache中查询是否命中,如果命中则把数据返回给CPU。如果L1 cache缺失,则继续从L2 cache中查找。当L2 cache命中时,数据会返回给L1 cache以及CPU。如果L2 cache也缺失,很不幸,我们需要从主存中load数据,将数据返回给L2 cache、L1 cache及CPU。这种多级cache的工作方式称之为inclusive cache。某一地址的数据可能存在多级缓存中。
与inclusive cache对应的是exclusive cache,这种cache保证某一地址的数据缓存只会存在于多级cache其中一级。也就是说,任意地址的数据不可能同时在L1和L2 cache中缓存。
exclusive cache的优点之一是多级cache可以一起存储更多的数据。一般使用inclusive cache类型,每次cache miss,可以从下一级的cache中寻找,load。而exclusive cache,每次cache miss,只能去main memory中load。但是exclusive cache比较节省cache size。
[53] 组关联映射中用于替换cache line的算法有什么不同?以下是一些可用于替换cache line的算法
LRU(Least Recently Used):将最近最少使用的内容替换出cache
MRU (Most Recently Used):与MRU,将最近经常的内容提出cache
PLRU (Pseudo LRU):关联性很大的时候,LRU的实现成本很高。如果实际情况在丢弃任一个最近最少使用的数据就能满足,那么伪LRU算法就派上用场了,它为每一个缓存数据设立一个标志位就可以工作。
LFU (Least Frequently Used):这个缓存算法使用一个计数器来记录条目被访问的频率。通过使用LFU缓存算法,最低访问数的条目首先被移除。这个方法并不经常使用,因为它无法对一个拥有最初高访问率之后长时间没有被访问的条目缓存负责。
Random replacement:在该算法中,不存储任何信息,并且在需要替换时选择一条随机行。
在多个处理器拥有自己的cache的共享多处理器系统中,相同数据(相同地址)的多个副本可能会同时存在于不同的cache中。 如果允许每个处理器自由更新cache,则可能导致内存视图不一致。 这称为高速缓存一致性问题。 例如:如果允许两个处理器将值写入同一地址,则在不同处理器上读取同一地址可能会看到不同的值。
[55] 基于监听和基于目录的缓存一致性协议之间有什么区别?Snoop based Coherence Protocol:来自处理器的数据请求将发送到共享系统一部分的所有其他处理器。 其他所有处理器都监听此请求,并查看它们是否具有数据副本并做出相应响应。 因此,每个处理器都需要维护存储器的一致性视图。
Directory based Coherence Protocol:目录用于跟踪哪些处理器正在访问和缓存哪些地址。 发出新请求的任何处理器都将检查此目录,以了解其他代理是否有副本,然后可以向该代理发送点对点请求以获取最新的数据副本。
| Snoop based Coherence | Directory based Coherence Protocol |
|---|---|
| 对于小的系统来说,如果带宽足够,基于监听的协议速度会更加快 | 基于目录的协议需要使用查找表,这将会导致较长的时延 |
| 基于监听的协议不适合大型系统,因为它需要将将每一个请求信息进行广播 | 由于不需要广播,基于目录的协议更加适合大型系统 |
MESI协议时多处理器系统中最常用的cache一致性协议。MESI 是指4中状态的首字母。每个Cache line有4个状态,可用2个bit表示,它们分别是:
| 状态 | 描述 | 监听任务 |
|---|---|---|
| M 修改 (Modified) | 该Cache line有效,数据被修改了,和内存中的数据不一致,数据只存在于本Cache中。 | 缓存行必须时刻监听所有试图读该缓存行相对就主存的操作,这种操作必须在缓存将该缓存行写回主存并将状态变成S(共享)状态之前被延迟执行。 |
| E 独享、互斥 (Exclusive) | 该Cache line有效,数据和内存中的数据一致,数据只存在于本Cache中。 | 缓存行也必须监听其它缓存读主存中该缓存行的操作,一旦有这种操作,该缓存行需要变成S(共享)状态。 |
| S 共享 (Shared) | 该Cache line有效,数据和内存中的数据一致,数据存在于很多Cache中。 | 缓存行也必须监听其它缓存使该缓存行无效或者独享该缓存行的请求,并将该缓存行变成无效(Invalid)。 |
| I 无效 (Invalid) | 该Cache line无效。 | 无 |
是对于MESI协议的扩展,引入了两个新状态“F”“O”:
F (Forward): 在MOESI协议中,S状态的定义发生了细微的变化。当一个Cache行状态为S时,其包含的数据并不一定与存储器一致。如果在其他CPU的Cache中不存在状态为O的副本时,该Cache行中的数据与存储器一致;如果在其他CPU的Cache中存在状态为O的副本时,Cache行中的数据与存储器不一致。
O (Owned): O位为1表示在当前Cache 行中包含的数据是当前处理器系统最新的数据拷贝,而且在其他CPU中一定具有该Cache行的副本,其他CPU的Cache行状态为S。如果主存储器的数据在多个CPU的Cache中都具有副本时,有且仅有一个CPU的Cache行状态为O,其他CPU的Cache行状态只能为S。与MESI协议中的S状态不同,状态为O的Cache行中的数据与存储器中的数据并不一致。
虚拟内存是一致内存管理技术,及时实际的物理内存很小,虚拟处理器也允许处理器查看地址的虚拟连续空间。操作系统管理虚拟地址空间以及从辅助设备(如磁盘)到物理主内存的内存分配。CPU中的地址转换硬件(memory management unit,MMU)将虚拟地址转换为物理地址。 此地址转换使用分页的概念,其中将连续的内存地址块(称为页)用于虚拟内存和实际物理内存之间的映射。
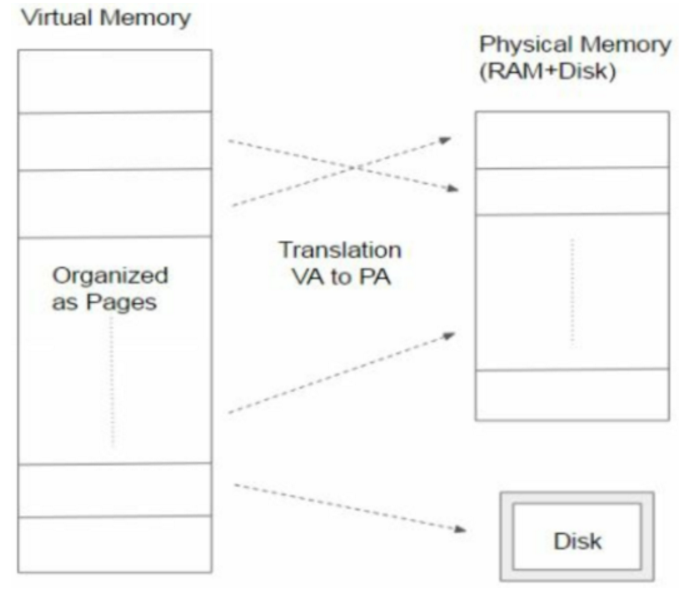
软件程序或进程用来访问其地址空间中存储位置的地址称为虚拟地址。 然后,操作系统连同硬件将其转换为另一个地址,该地址可用于实际访问DRAM上的主内存位置,该地址称为物理地址。 地址转换是使用分页的概念完成的,如果主内存或DRAM没有此位置,则在OS的协助下,数据将从辅助内存(如磁盘)移至主内存。
[59] 什么是页的概念?所有虚拟内存都将虚拟地址空间划分为页,页内的虚拟内存地址是连续的。页是内存从辅助存储移动到物理内存以管理虚拟内存的最小单位。大多数计算机系统的页至少为4KB.当需要更大的实际内存是,某些结构还支持更大的页。页表用于将应用程序看到的虚拟地址转换为物理地址,是一种数据结构,用于多页情况下,在内存中虚拟地址到物理地址的映射。
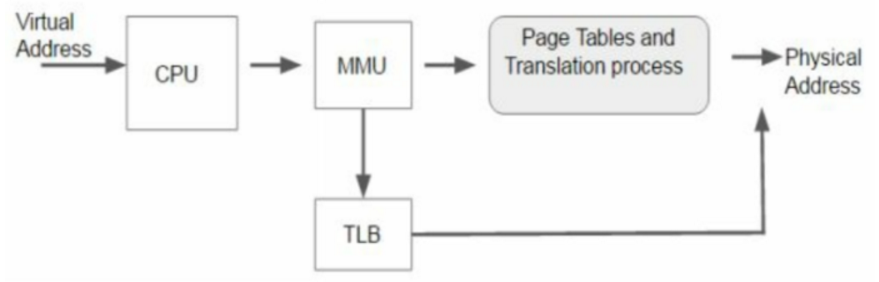
[60] 什么是TLB?TLB: Translation Lookaside Buffer。根据功能可以译为快表,直译可以翻译为旁路转换缓冲,也可以把它理解成页表缓冲。里面存放的是一些页表文件(虚拟地址到物理地址的转换表)。当处理器要在主内存寻址时,不是直接在内存的物理地址里查找的,而是通过一组虚拟地址转换到主内存的物理地址,TLB就是负责将虚拟内存地址翻译成实际的物理内存地址,而CPU寻址时会优先在TLB中进行寻址。处理器的性能就和寻址的命中率有很大的关系。
当程序访问映射到虚拟地址空间但未加载到主存储器中的内存页时,计算机硬件[内存管理单元(MMU)]会发起中断。 此中断称为页面错误。
[62] 如果CPU正在执行一个任务,如何停止他并运行另一个任务?可以使用外部中断源来中断CPU上的程序执行。
[63] 什么是中断和异常,它们有何不同?中断是一个异步事件
通常由外部硬件(I / O设备或其他外围设备)生成,并且不会与指令执行边界同步。例如:键盘,存储设备或USB端口可能会发生中断。当前指令执行结束后,总是对中断进行服务,并且CPU跳转到执行中断服务程序。
异常是一个同步事件
异常当处理器在执行指令时检测到任何预定义条件时生成的同步事件。例如:当程序遇到被零除或未定义的指令时,它将生成异常。异常又分为三种类型,程序流的改变方式取决于类型:
故障:在发生故障的指令之前由处理器检测到故障并对其进行维修
陷阱:在导致陷阱的指令之后对陷阱进行维修。最常见的陷阱是用于调试的用户定义中断。
中止:中止仅用于在执行不再继续的情况下发出严重的系统问题信号
向量中断是一种中断,终端设备使用该中断特有的代码将处理器定向到正确的中断服务程序中,该代码由中断设备与该中断一起发送给处理器。
而非向量中断,中断服务程序需要读取中断寄存器,解码出导致中断的中断源,然后执行特定的中断服务程序
[65] 有哪些技术可以提高从内存提取指令的性能?指令缓存和预取
指令缓存和预取算法将在实际的指令解码和执行阶段之前继续提取指令,这可以较小设计中指令提取阶段的存储等待时间延迟。
分支预测和分支目标预测
分支预测基于历史指令预测是否将发生条件分支,而分支目标预测将有助于在处理器计算之前预测目标。 这能最大程度地减少指令提取停顿,因为提取算法可以根据预测保持提取指令。
[66] 内存映射I/O(memory mapped I/O,MMIO)是什么意思?Memory Mapped I/O (MMIO)是一种在CPU与I/O或外围设备之间执行输入/输出(I/O)的方法.CPU使用相同的地址总线来访问内存和I/O设备(包括I/O设备内部的寄存器或内部的任何内存)。在系统地址映射中,为I/ O设备保留了一些内存区域,并且当CPU访问该地址时,响应访问并监视该地址总线的相应I/ O设备。例如:如果CPU具有32位地址总线:它可以访问0到2^32之间的地址,并且在该区域中,我们可以为一个或多个I/O设备保留地址(例如0到2^10)。
[67] 独热码在设计中有什么好处?独热码中,状态转换时,会有两位改变,一位清零,一位置一。它的优点时,不需要进行解码就能知道当前的状态。独热码会使用更多的触发器,但是更加少的组合逻辑,在时序电路中不需要用解码逻辑进行区分状态。

 /2
/2 


 eetop公众号
eetop公众号 创芯大讲堂
创芯大讲堂 创芯人才网
创芯人才网